AtmaCup11
ぐるぐるさんが主催するKaggleみたいなデータコンペティション"AtmaCup11"に同じ大学の友達と参加してきました!
 ぼくらのチームは14位で敢闘賞でした!
ぼくらのチームは14位で敢闘賞でした!
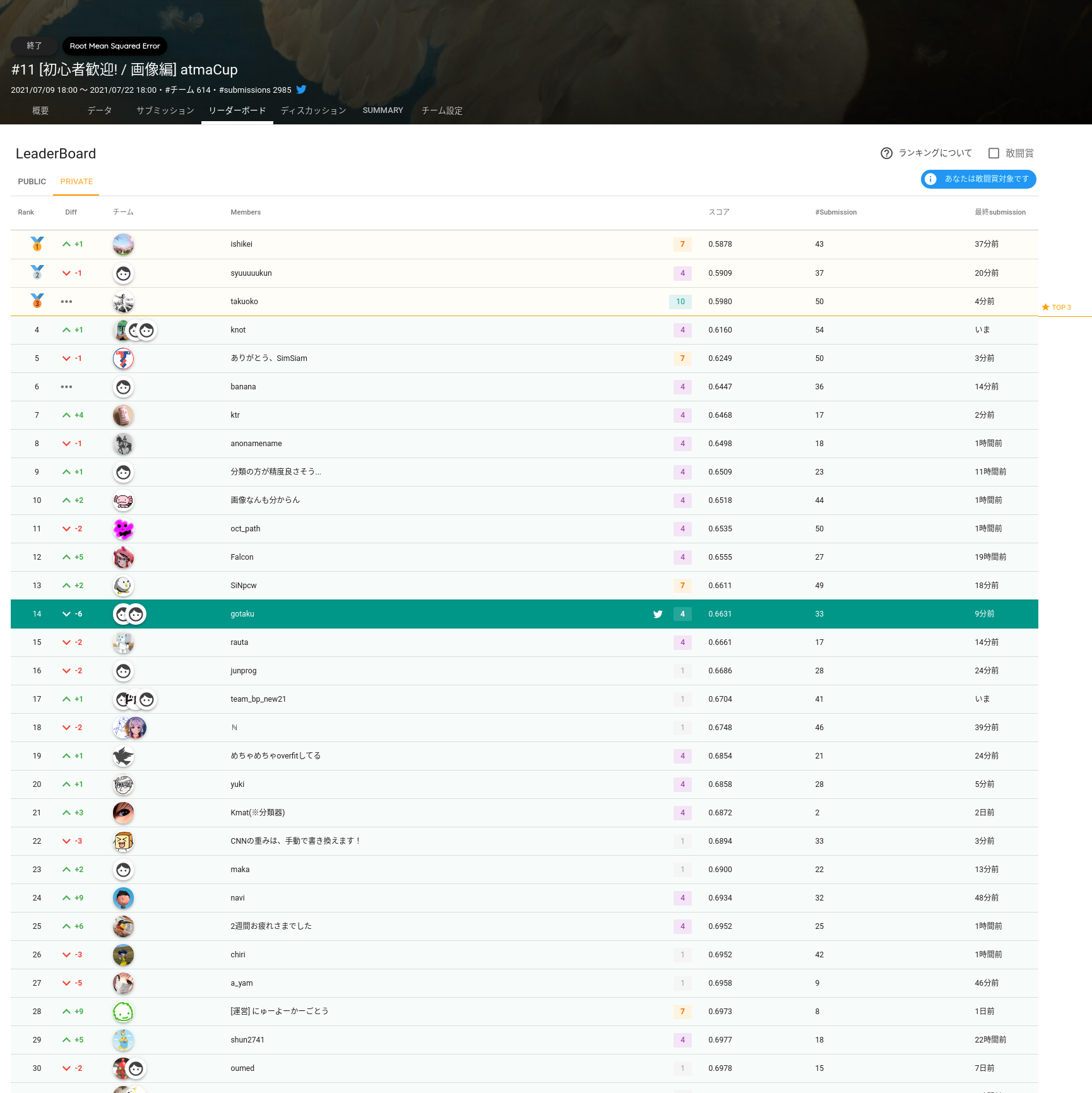 100分の1の精度を争う熾烈な戦いでした!
今回の内容が「美術作品の画像やメタデータからその作品がどの時代に作成されたのかを予測する。」という内容で、これまでの画像の研究内容がどれだけ発揮できるかウキウキしてました!はじめのうちは...
100分の1の精度を争う熾烈な戦いでした!
今回の内容が「美術作品の画像やメタデータからその作品がどの時代に作成されたのかを予測する。」という内容で、これまでの画像の研究内容がどれだけ発揮できるかウキウキしてました!はじめのうちは...
Kaggleの知識
これまでKaggleに参加したことがなかったので、Kagglerについていくのに精一杯でした!一緒に参加した子はもう慣れてて、「良し!じゃあEDAしながら、CVとLBの結果比較してこっか!」って言われて...むむむ〜〜ってなってました(泣)
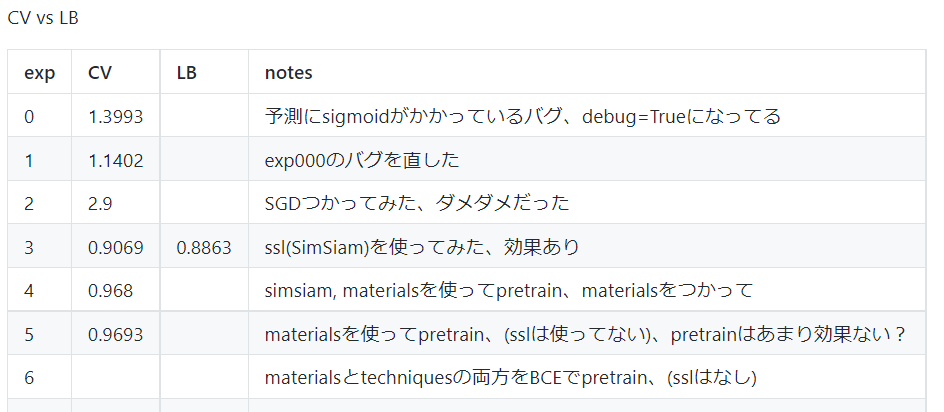 こんな感じでぐわ〜〜といろんな手法を試していった!
こんな感じでぐわ〜〜といろんな手法を試していった!
Kaggleで大切なのは、Disscusionを有効に活用することだと教わり、他の参加者の人たちのコメントとか参考に進めていったけど、これがまたすごい!EDAっていうデータ解析ではさ、用いるデータセットはどんな相関があってどういう分布をしていて... とか当たり前のように議論されて、は〜〜!って思った!
この時点で、「あ〜、これまで自分がデータサイエンス力って大したこと無いんだな〜」って痛感させられた...
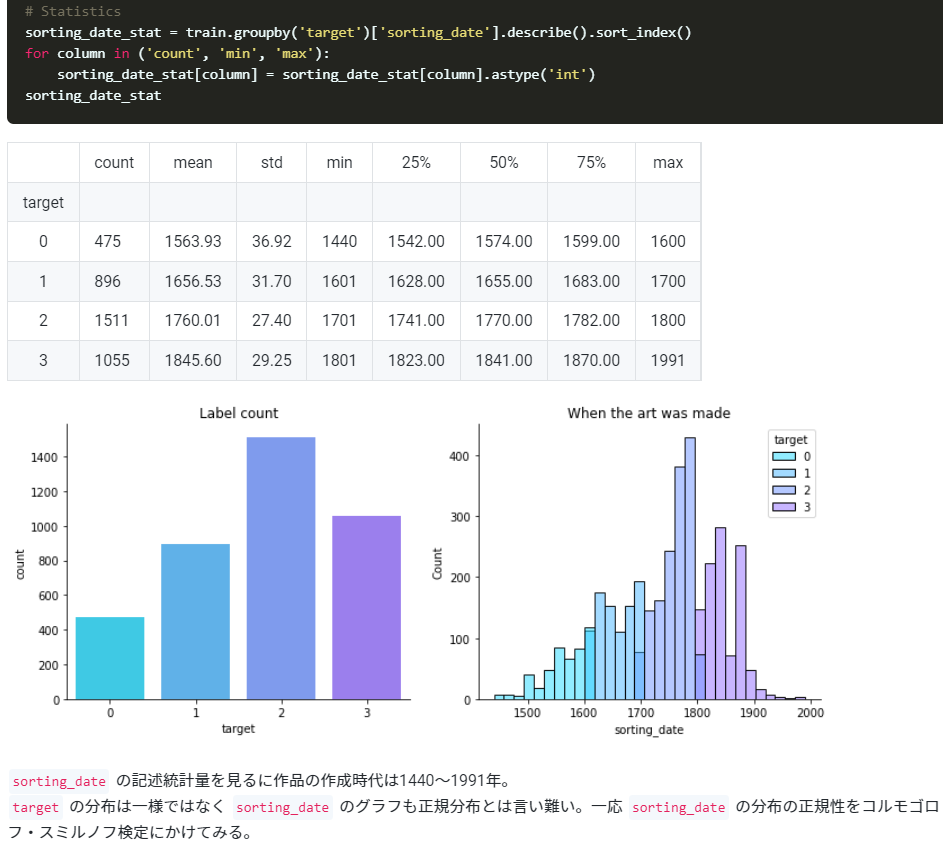 実際にDiscussionされてたEDAの中身
実際にDiscussionされてたEDAの中身
ネットワーク
今回のDiscussionでもっともいいねがついたのが、「自己教師学習(SSL)の効果」であり、メンバーの子が「よし!ぼくらもやろう!」ってことで早速、導入した!このときの彼の動き出しの速さはまじでびっくりした!
SSLもSimSiamとかESViTとか最新の手法がバンバン議論されてて、「よし!全部ためそう!」って言われたから「まじか!」っと思った!(汗)これがKagglerなのかと息を呑みましたね...
ほいで、最終的にはこれまで試した手法をもとにアンサンブルでゴリ押しするというもの!
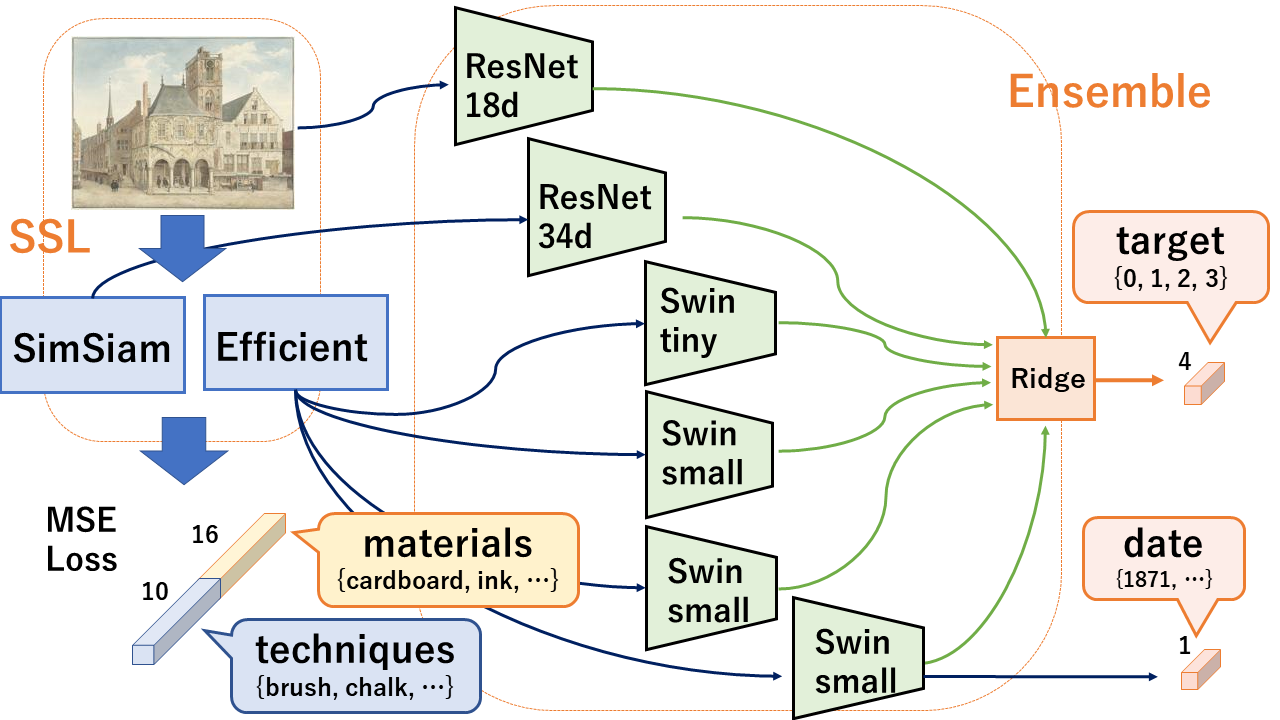 最終的なネットワーク
まあ、アンサンブルするっていっても、そこはKaggle!どのモデルとどのモデルは相関があるかをしっかり分析して行った!はじめにメンバーの子が分析している内容を参考にしたけど、こういうのを当たり前のようにやってるのが、本当にすごいと感じた!
最終的なネットワーク
まあ、アンサンブルするっていっても、そこはKaggle!どのモデルとどのモデルは相関があるかをしっかり分析して行った!はじめにメンバーの子が分析している内容を参考にしたけど、こういうのを当たり前のようにやってるのが、本当にすごいと感じた!
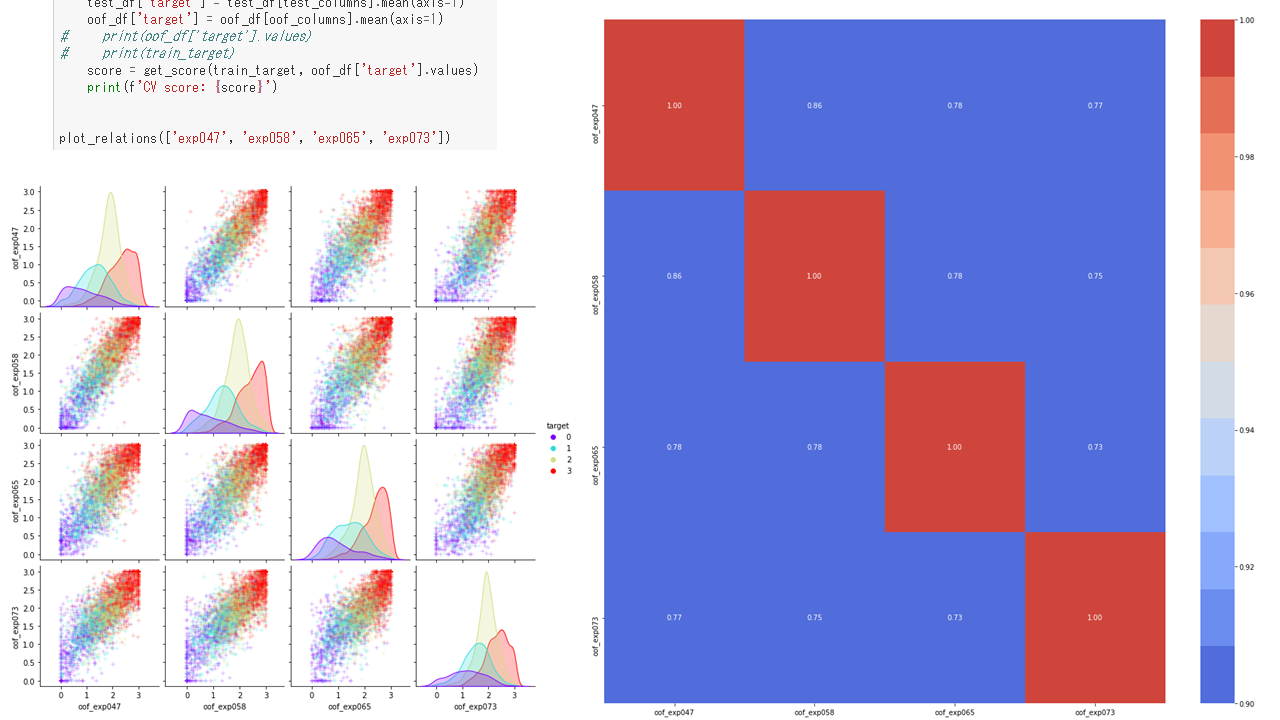 どのモデルをアンサンブルするか定量的に判断!
どのモデルをアンサンブルするか定量的に判断!
atmaCupを通して
「データサイエンスやるならKaggle」って言われる所以がよくわかった!ものすごい密度な2週間だった!自分が知らない内容が数時間単位で更新されてて、もうオーバーフロー状態だった!でも、やってよかったなって本当に思った。
これからKaggleのコンペにバンバン出て、もりもりと自分のデータサイエンティスト力を磨いていこうと思いました!!かとちゃん!一緒にやってくれてありがとう!
参考資料cf) atmaCup11
cf) 今回の内容のGitHub