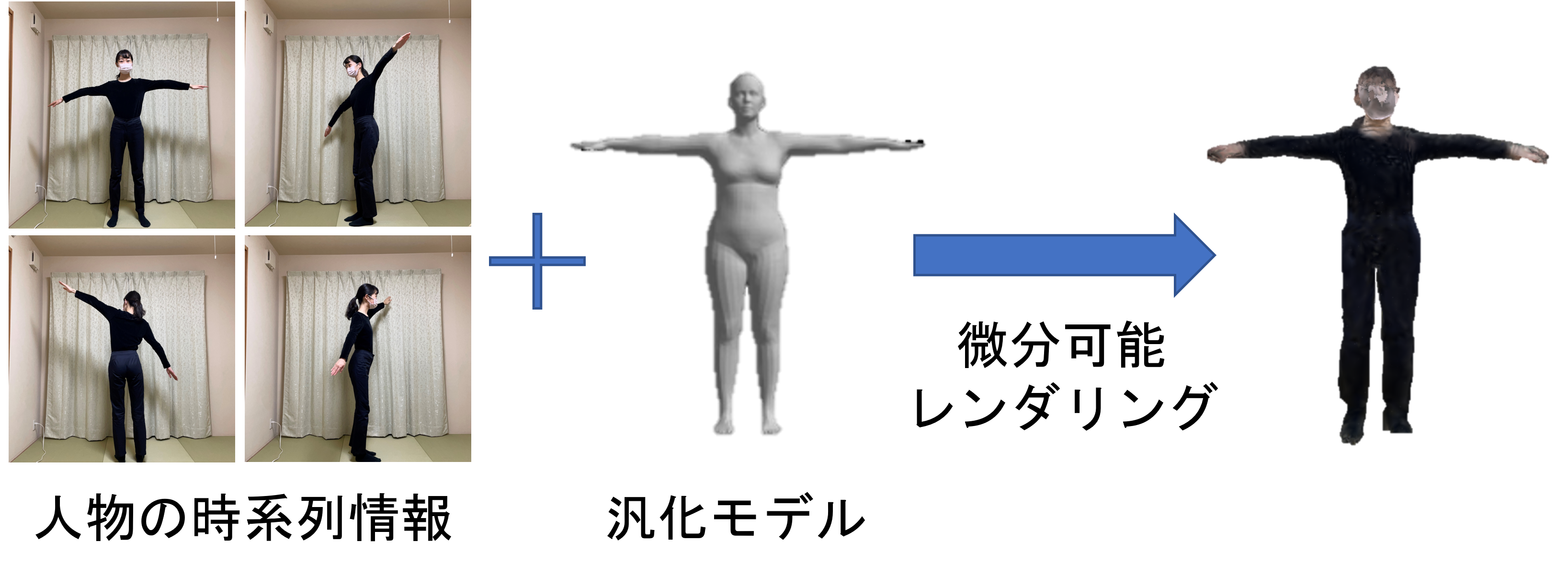サッカーにおける非ボール保持者のいと推定
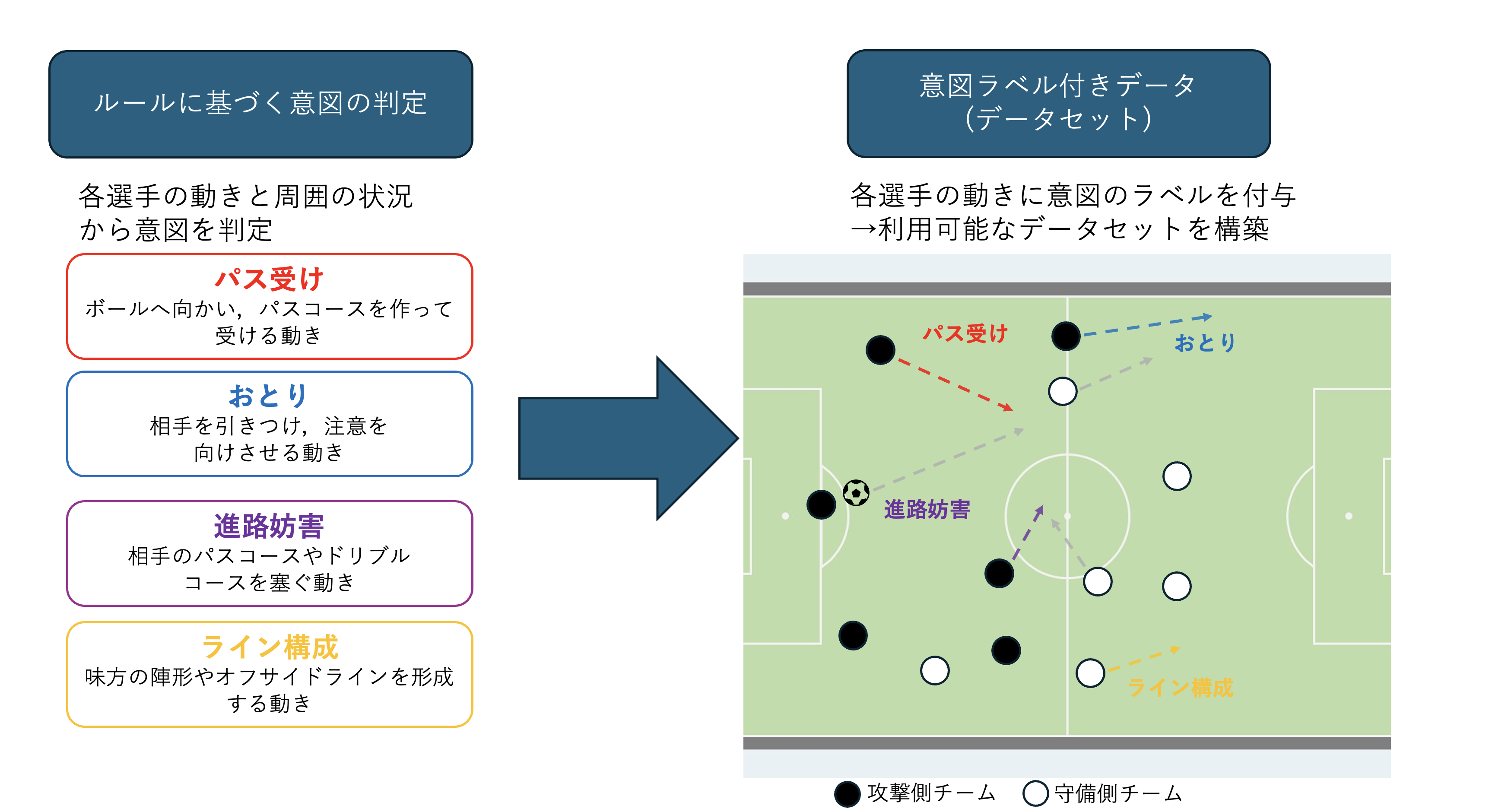
サッカーの試合において、ボールを持っていない選手(非ボール保持者)の動きは、パスコースの形成や守備の引きつけなど、試合の流れに大きく影響します.しかし、こうした選手の「意図」を定量的に扱った研究はこれまで存在していませんでした.そこで本研究では、このような意図の解析を行うことを前提に,トラッキングデータに対して非ボール保持者の意図を「パス受け」「おとり」「進路妨害」「ライン構成」の4種類の意図ラベルを付与したデータセットを構築しました.
このデータセットでは,DFL(Deutsche Fußball Liga)の7試合から3000シーンを抽出し,それぞれのシーンにおいて各選手に上記の意図を付与しました.
この意図ラベルの妥当性を検証するため,TimesNetを用いた意図識別器で選手の軌跡情報から意図の推定を行いました.その結果,すべての条件でランダム識別を上回る性能が得られ,ここで定義した意図が行動と相関を持つことを確認しました.また、最適なフレーム長は意図の種類によって異なることなどを確認しました.今後はこのデータセットを基盤として,より高精度な意図の推定を行う方法について検討を行う予定です.
震度情報と音響情報の整合性に着目した死角物体の検出
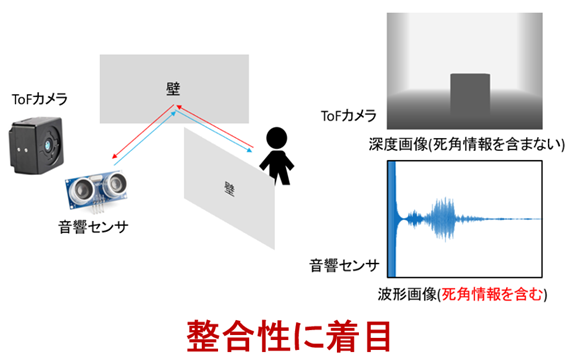
近年,自動運転やロボット分野において周囲環境の高精度な把握が求められているが,壁や障害物によって生じる死角領域の観測は依然として困難である.そこで本研究は,音響センサとToFカメラを組み合わせ,死角に存在する物体を検出する手法を提案する
音響センサは死角物体から情報を取得可能である一方,ToFカメラなどの光学センサは死角領域の情報を直接取得することが難しい.そこで本研究では,光学センサから得られる深度画像と音響センサから得られる音響情報の整合性に着目する.具体的には,深度画像を入力としてcGANを用い,対応する音響スペクトログラムを生成する.死角に物体が存在しない場合には生成結果と観測音響は整合するが,物体が存在する場合には不整合が生じる この整合性に着目することで,死角物体の有無を検出する.
実験を行った結果,深度画像から音響情報を生成して整合性の判定を行うことで,深度画像を直接利用するよりも高精度に死角物体を検出可能であることを確認した.
感情推定に基づく触覚画像の最適化
VR空間などでは触覚の共有が難しく、触覚画像と呼ばれる画像を提示することで視覚情報のみで触覚を再現する疑似触覚技術が注目されています. しかし、触覚は主観的なものであるため定量的に測定・再現することは困難です. 加えて、触覚には個人差があ るため、疑似触覚による触感の再現の際に、各ユーザに最適な触感を与えることは困難と なっています.
そこで、本研究ではユーザの顔の動画像を用いて感情推定を行い、その推定結果に基づいて触覚画像の最適化をする手法を提案します. 感情推定には VideoSwinTransformerを用いてValence と呼ばれる快・不快の度合いを表す値を推定し、触覚画像の最適化には VisionTransformer を用いた拡散モデルを用います.
この2つの方法により Valence の推定値を目標値に近づける ように触覚画像を制御することで触覚画像の最適化を行います. 実験の結果、Valence を目 標値に近づくように触覚画像を制御できることを確認しました. これにより、疑似触覚を用 いて各個人に最適な触感を提供することが可能となります.
サッカー動画に基づくファウルの自動判定
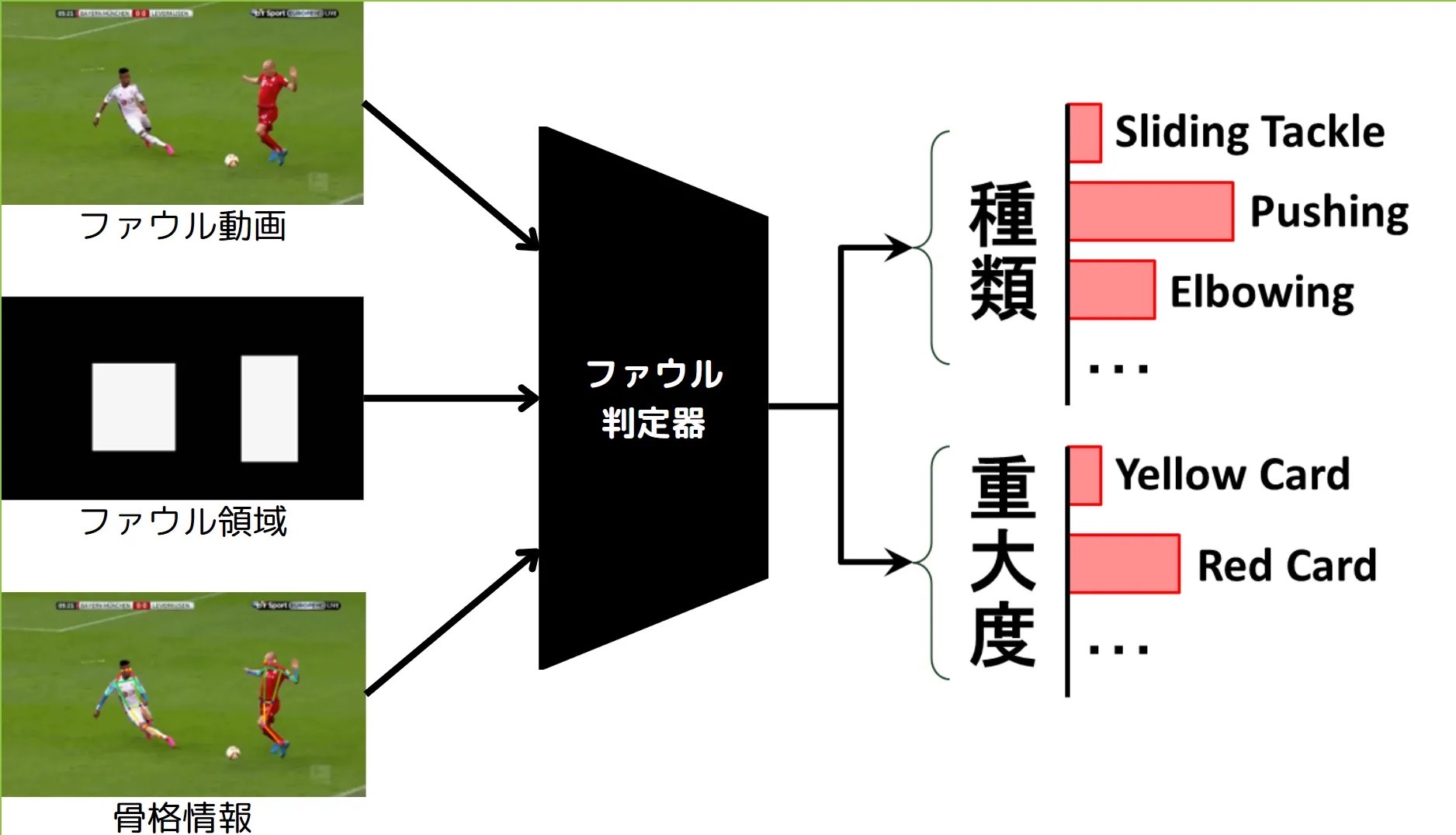
本研究では,サッカーの試合映像からファウルに関与する人物,ファウルの種類,さらにその重大度を自動判定する手法を提案しています.近年,サッカーではゴールラインテクノロジーやVARシステムなどの技術を活用した審判支援が導入されています.しかし,これらが利用可能なシーンは限定的であり,すべてのシーンで利用可能なわけではありません.
特に,複雑な接触を伴うファウルプレーの判定は依然として人間の審判に委ねられているのが現状です.しかし,試合展開が速いサッカーにおいて,審判が見逃してしまうファウルや,複数の選手が密集する状況での正確な判定は困難であり,この支援は重要な課題となっています.
そこで本研究では,深層学習技術を用いて試合映像からファウルの自動検出と判定を行う手法を提案しました.この方法ではまず,ファウルに関与する選手の領域を特定し,その上で対象選手の骨格情報を推定します.これらの情報を統合してニューラルネットワークにより解析することで,ファウルの種類と重大度を同時に判定します.
この技術により,より客観的で一貫性のあるサッカー審判支援が可能になると期待できます.
HDR画像撮影のための分光感度特性の最適化
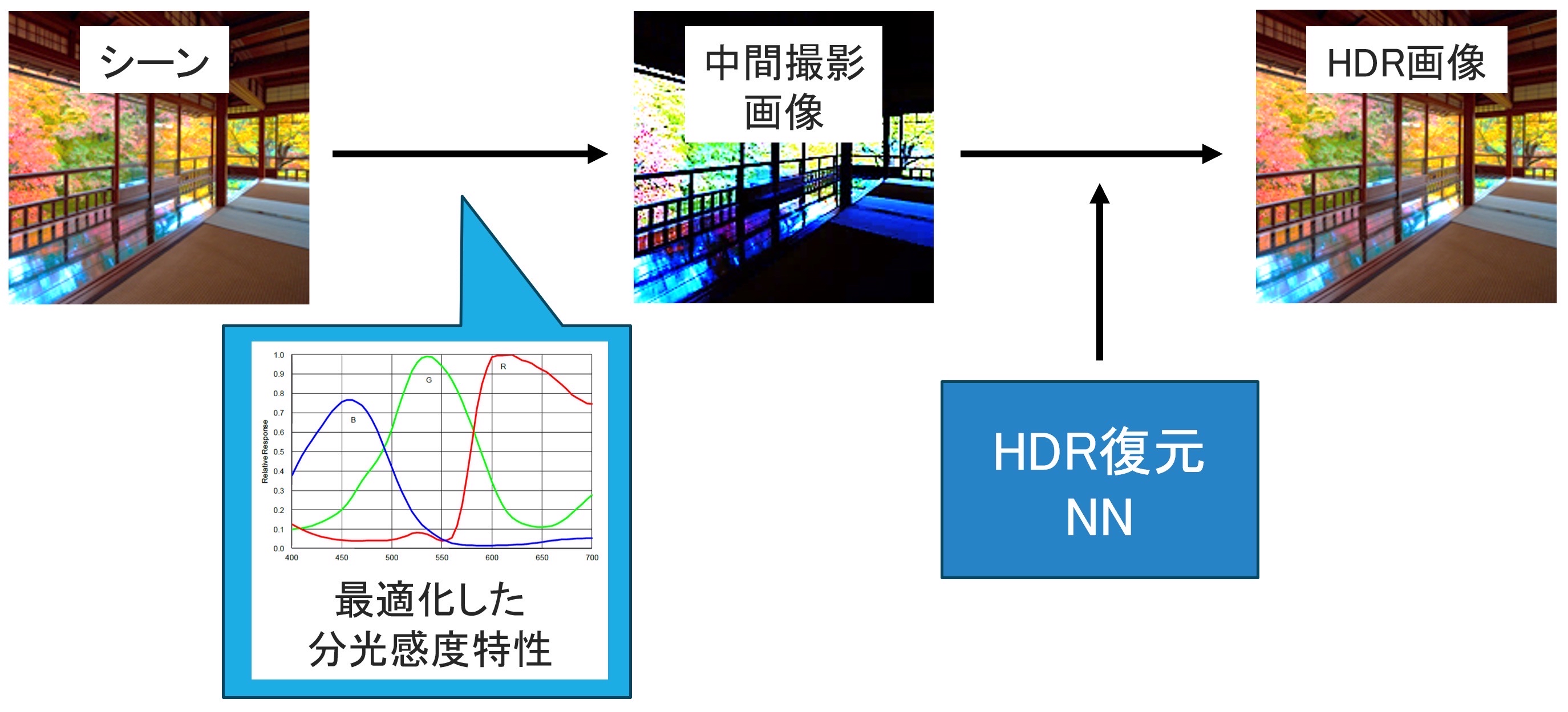
近年,現実世界の広大な輝度範囲を忠実に再現可能とするHDR(High Dynamic Range)画像技術は,映像,医療,監視,文化財保存など,幅広い応用分野において重要な役割を果たしています.従来のHDR画像撮影法では複数露光による撮影と合成が主流ですがが,動的シーンに対してはゴーストやブレの問題が発生しやすいという問題がありました.
そこで本研究では1度の撮影のみでHDR画像を取得する方法を目指しました.そのために,撮像素子の分光感度特性をHDR再構成に適した形へ最適化する方法を提案します.この提案法では,新しい分光感度特性を既存の分光感度特性を線形和により表現することで,これまでに撮影された画像群から分光感度特性と復元モデルを同時に学習すること可能にしました.
実験の結果,一度の撮影でHDR画像が得られることを確認しました.
今後は,実際にカメラへの搭載や,復元ネットワークのへ変更などの検討を行います.
サッカー映像を対象とした自動実況生成
サッカー中継において実況は、視聴体験を向上させるだけでなく、競技自体の普及にも貢献しています。しかし実況が付けられるのは、注目度の高い一部の試合に限られています。そこで本研究では、サッカー映像から自動で実況を生成するシステムを構築することで、実況にかかるコストをなくし、
アマチュアや学生リーグの価値向上を目指しました。画像からの説明文生成(画像キャプショニング)においてはTransformerと呼ばれるニューラルネットワーク構造がよく用いられますが、サッカーの試合映像は広範囲を撮影するためにある程度離れた位置から撮影されており、通常の画像キャプショニングのみでは十分な解析が行えません。
そのため、本研究においてはサッカーコート内の状況をより詳細に実況に反映するため、選手の位置や動きといった試合状況をグラフ構造で表現・解析し、これを映像と併用することで、精度の高い実況生成を実現しました。実験では、画像のみを使った場合と、画像と解析した情報を使った場合で定量評価を行い、提案手法が優れた性能を示しました。
今後は語彙の最適化やアクションスポッティング精度向上に取り組み、さらなる実用性向上を目指します。
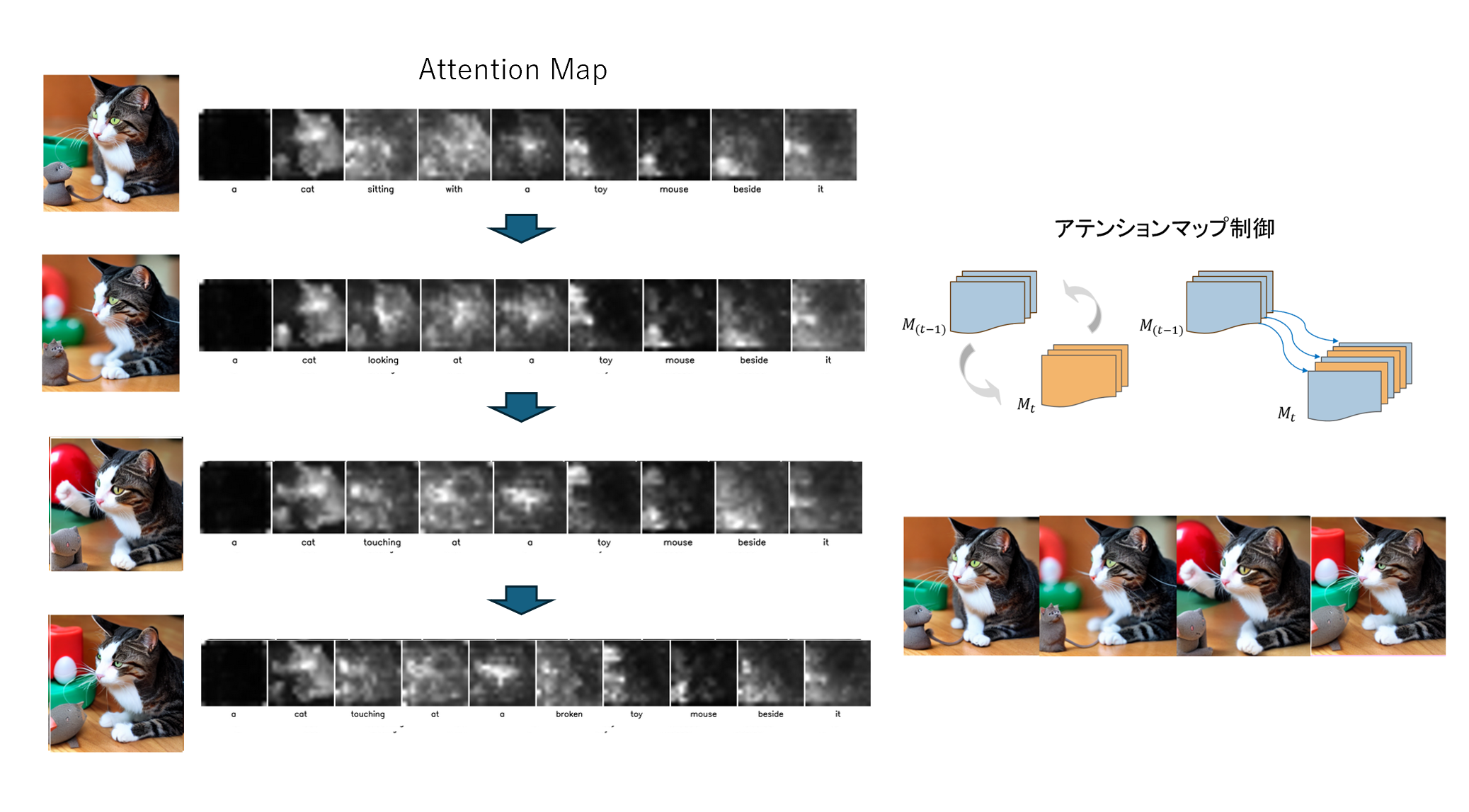
アテンション制御による長時間の動画のキーフレーム生成
本研究は、ニューラルネットワークを用いて,一貫性のある長時間動画を作成するための方法を提案します.
近年の動画生成においてはStable Diffusionと呼ばれるモデルが広く利用されていますが,これまでに提案された方法では前後のフレームのつながりがあまり重視されていないため,動画の前後で辻褄の合わない一貫性のない動画像が生成されることが多く存在しました.
そこで本研究では,キーフレームと呼ぶ動画像内の重要なフレームの生成時に過去フレームのアテンションマップを参照・制御することで、構図やオブジェクトの視覚的統一性を維持する方法を示しました。また、前後のフレーム間の画像類似度を向上させるように強化学習により
プロンプトを最適化することで、意味的一貫性の高い画像生成を実現しました。これにより、長時間映像に必要な一貫性のあるシーン設計を可能にし、映像制作、アニメーション、教育・医療分野のコンテンツ生成などへの応用を期待できます.
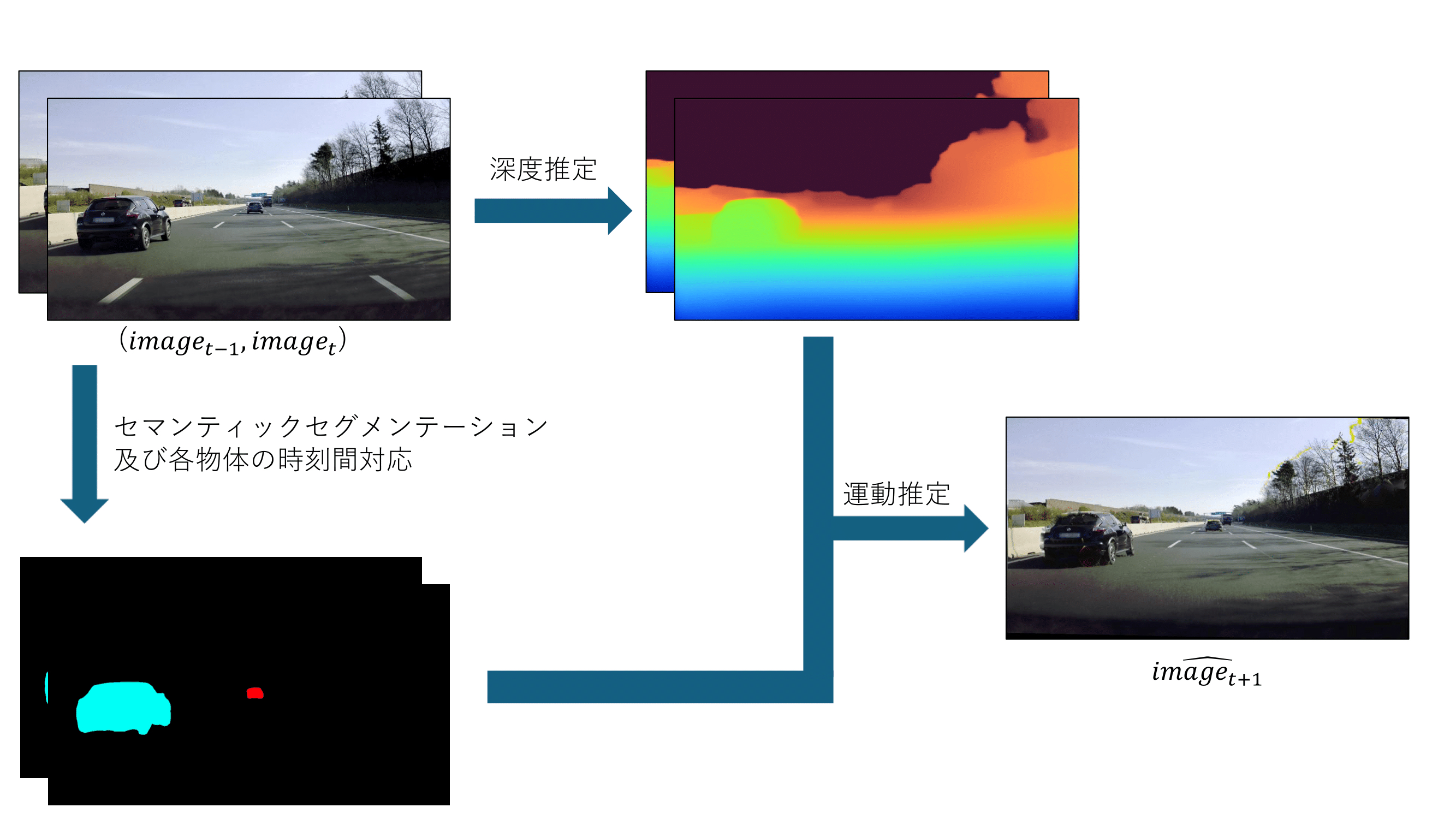
単眼車載映像における3次元運動を考慮したリアルタイム未来映像予測
本研究では,遠隔操作等における映像の遅延を補償することを目的とし,これまでに得られたビデオ映像に基づく未来映像を生成する方法を提案します.
近年,自動運転や遠隔操縦技術の発展により,カメラ映像を用いた制御が注目されています.しかし,映像の取得やその処理には必ず一定の処理時間が必要となり,その結果,処理結果は必ず現実世界から遅れた形で得られることになります.
自動運転などにおいてはこのような処理の遅延が重大な結果を引き起こすことがあるため,何等かの方法でこれを短縮,あるいは補償する必要があります.本研究では.この遅延を補償するために未来の映像を予測する方法を検討しました.
特に本研究では,車載単眼カメラ映像を対象とし,リアルタイムに未来映像を予測する手法を提案します.この方法ではまず,単眼深度推定により画素ごとの3次元情報を取得します.さらに,セマンティックセグメンテーションと呼ばれる方法により,
撮影された対象を物体ごとに分離します.このように分離された物体ごとに運動推定を行い未来映像を生成することで,リアルタイムでの未来映像生成を実現しました.
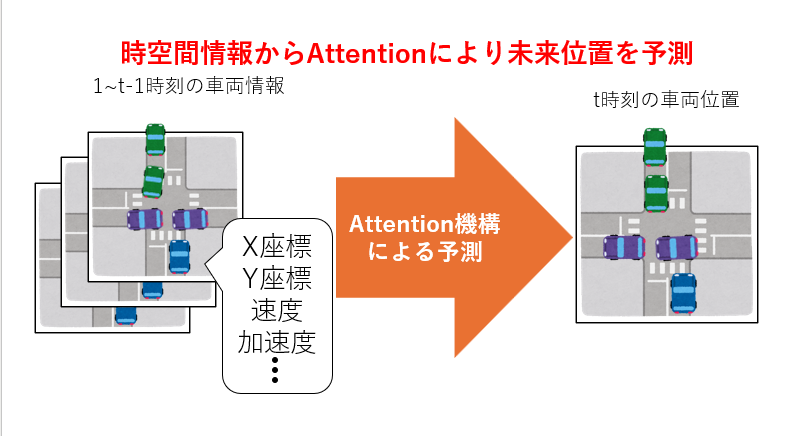
未来映像生成のための時空間Attentionを考慮した車両行動の予測
近年遠隔操作を用いる技術は,遠隔での探索,捜査などに利用されており社会の基盤に組み込まれつつあります.
このような技術は遠隔地で撮影された画像に基づき操作を行いますが,画像の撮影,送信には必ず一定の時間が必要となるため操作者が見る映像は必ず遅延してしまいます.
そのため,自動車の運転などを遠隔操作により行おうとすると,この遅延が重大な問題を引き起こしかねません.
そこで本研究では,特に車載カメラ映像において特に重要となる車両の運動に着目し,その運動予測を実現する方法を検討しています.
この方法では,Transformerと呼ばれる技術を用い,車両情報を時間軸上,空間上,自車両の情報の中でどの情報が重要であるかを推定し,得られた特徴の中からその時に重要な情報の選択を行うことで情報を効率よく使用して予測する手法を検討しています.
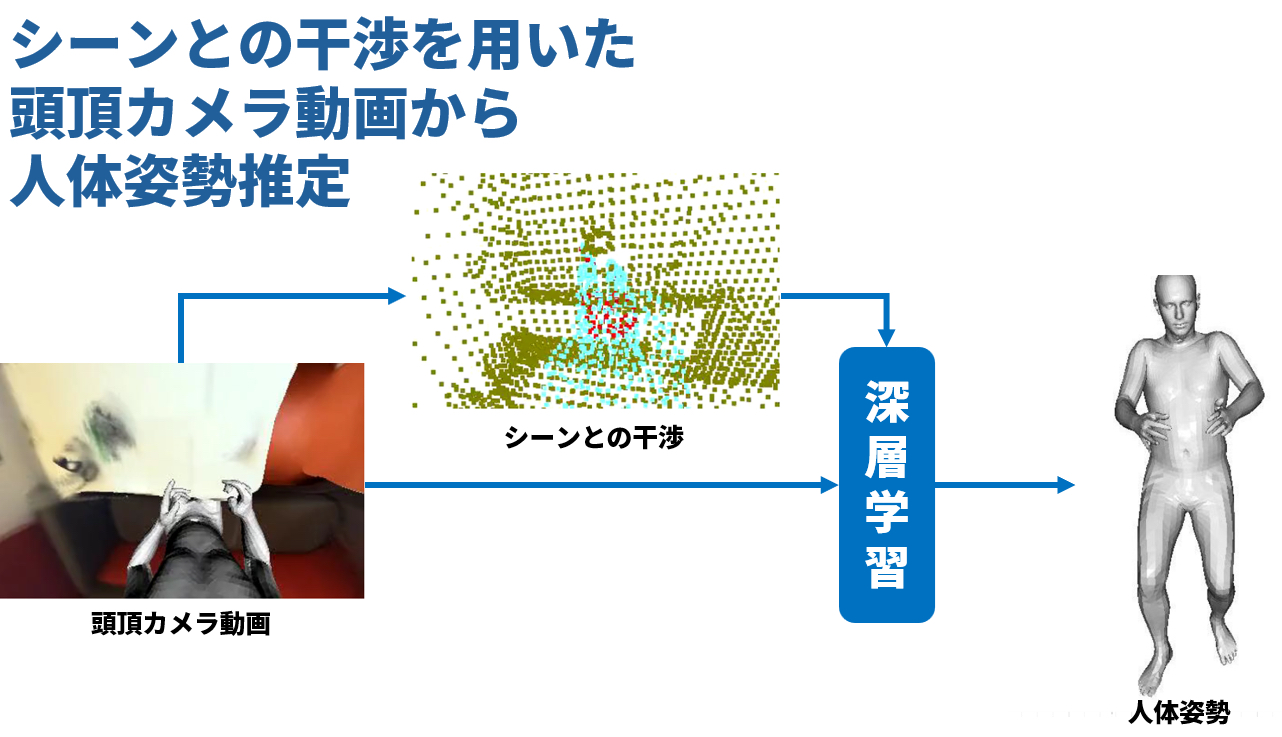
シーンとの干渉を用いた頭頂カメラ動画からの人体姿勢推定
この研究では,頭頂カメラで収集した動画像から人体の姿勢推定を行う際,人体とシーンとの干渉に着目することで高精度な姿勢推定を実現する方法を提案します.
頭頂カメラを用いて人体を撮影すると,1枚の画像のみで全身を撮影することができるため,軽装でのモーションキャプチャを実現できます.
しかし,頭頂カメラからの視点では,被写体の一部が隠れるオクルージョンがより顕著になり,推定精度の低下が起こるため,この隠れ部分についてはある程度の予測が必要となります.
そこで本研究では,このような予測を深層学習に基づいて行うとともに,人体と3次元シーンとの干渉に着目する,すなわち3次元的な重複が発生しないことを条件とすることで,より高精度な人体姿勢推定を実現しました.
実験の結果,干渉を用いた提案手法の方が従来の手法よりも高精度な推定が可能であることが示されました.
これにより,頭頂カメラから得られる動画から,より正確な姿勢推定を行うことが可能となりました.
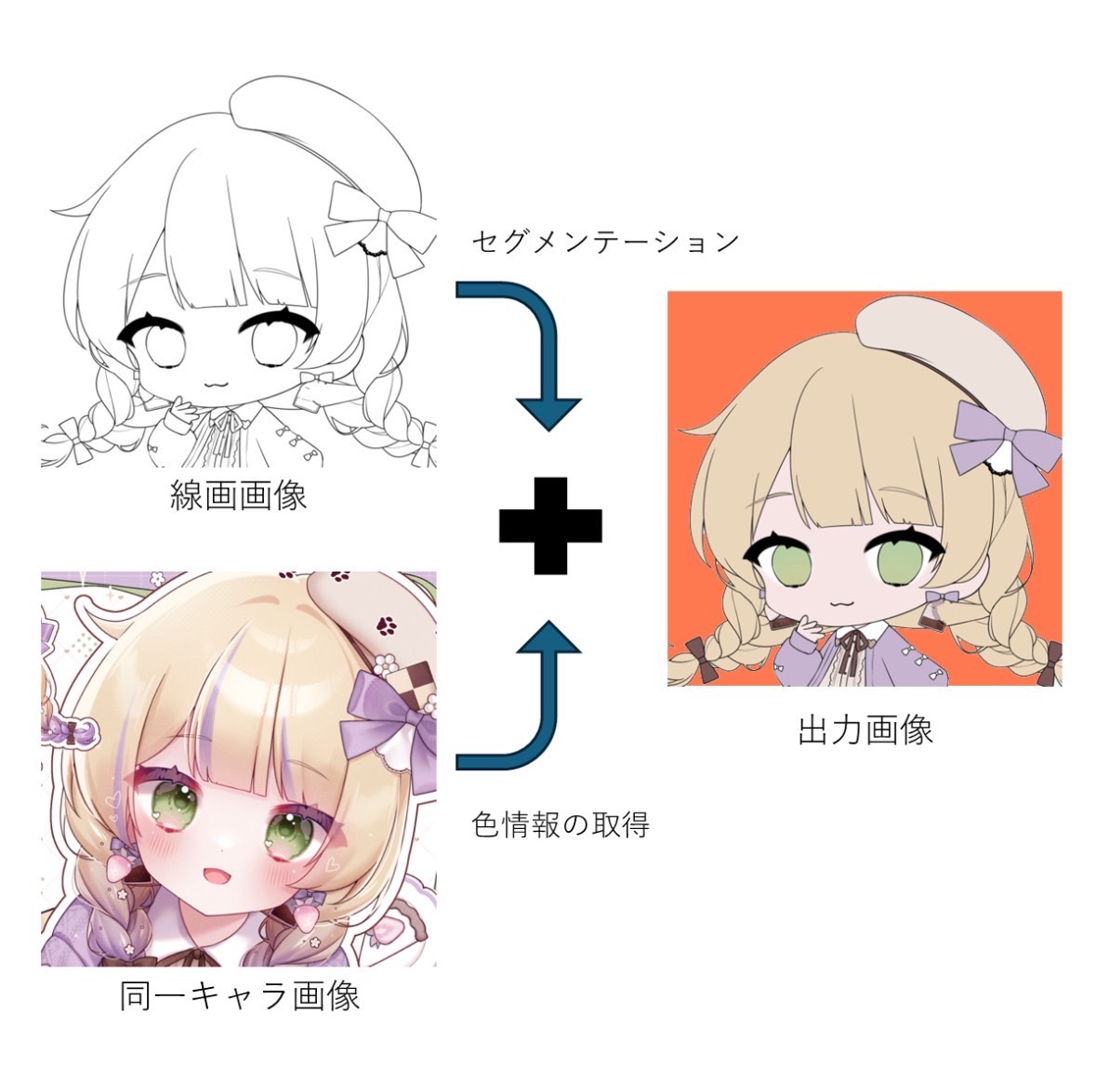
イラスト画像における自動着彩とレイヤー分割
本研究では,イラスト画像における作者の個性を加味した自動着彩とレイヤー分割についての研究を行っています.
イラスト制作は主にラフ・線画・下塗り・本塗りの4段階で行われます.
このうち下塗り作業は,描き手の個性が色という形で表出する大切な作業であるにもかかわらず,はみ出しや塗り残しの可能性があり作業コストが大変高いものになっています.
そこで本研究では,描き手の過去のイラスト画像から各パーツの下塗りに用いられた色を推定し,新しい線画画像へ下塗りを反映させる手法を提案します.
また,出力結果も画像ではなくパーツごとにレイヤー分割を行った状態で出力することで,創作活動での円滑な作業を補助することが可能になっています.
今後はさらに細かいパーツとの対応を取得することを目的とし,より高精度な下塗り画像を出力する方法について検討を行います.
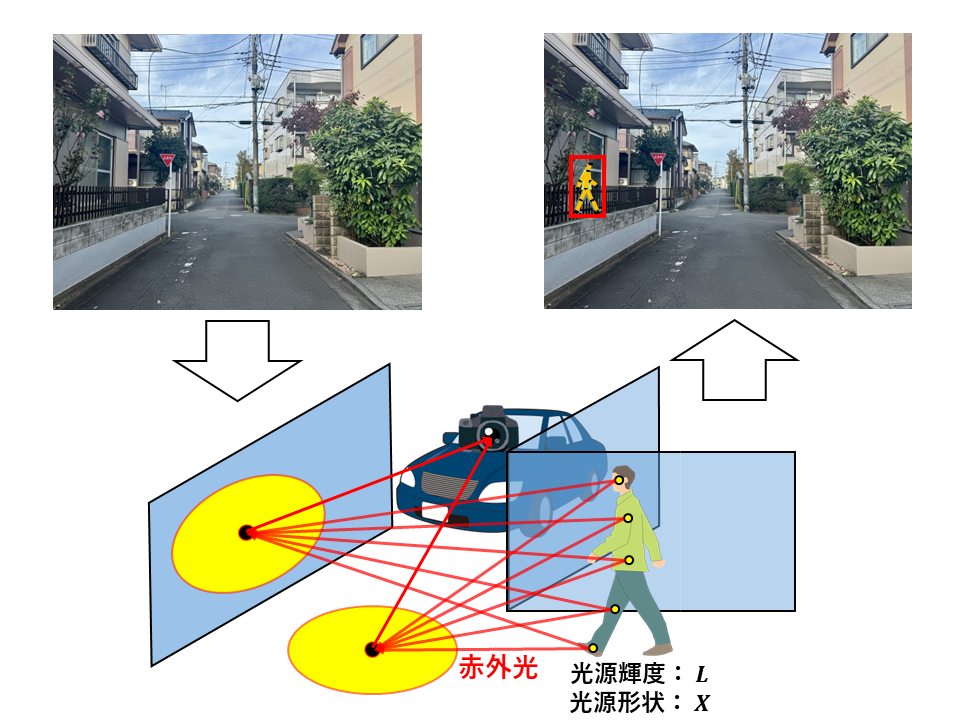
他車両への映り込みを用いた隠れた人体の位置推定
近年多数発生している交通事故の主な原因にドライバーの観測ができない範囲となる死角がある.
本研究では,この死角に潜む人物を他車両のボディの映り込みから検出する方法を提案する.
現在,精力的な研究開発により自動車の運転支援技術は日々進歩している.
しかし,依然として多くの交通事故が発生しており,さらなる技術の進歩が期待されている.
その原因の1つにドライバーの観測ができない死角と呼ばれる領域がある.
例えば,T字路などの見通しの悪い道路では多くの死角が発生し,そこから飛び出してくる歩行者との接触事故などが多く発生している.
本研究ではこのような問題の解決に向け,車載カメラ画像から映り込んだ人体を検出し,その人体の道路上での位置を推定する手法を提案する.
そのために,深層学習を用いて車載カメラ画像から他車両に映り込んだ人体を検出し,人物の道路上での3次元位置推定を行う.
この手法によって,運転手は死角に存在する人体を早期に認識し,未然に事故を回避することが可能になると期待される.
複数の反射面を用いた隠れた物体の3次元復元
本研究では,壁や地面など複数の反射面に反射する光から,隠れた物体を復元する手法を提案しています.
近年,交通事故の件数は減少傾向にありますが,依然として年に数十万件以上の事故が発生しています.
特に,自動車から死角となりやすい交差点では事故が絶えません.
死角の物体を復元する手法は一般にNLoSと呼ばれていますが,既存のNLoSでは得られる情報の少なさを補うために特殊なアクティブ計測系を用いて,単一の反射面から隠れた物体を復元する手法がほとんどでした.
そこで,本研究では受動的な情報のみから高精度なNLoSを実現するために,物体から照射された光は壁や床面など複数の反射面で反射されることに着目し,受動的に得られた画像から隠れた物体を3次元復元する手法を研究しています.
複数の反射面を用いることで,単一の反射面を用いるよりも高精度の復元ができることが期待できます.
また,赤外線カメラを用いることで人などの発熱物体を光源として扱うことを可能にします.
この手法により,死角が原因となる事故を減らすことを目的としています.
運動動画像からの時刻ごとの人物姿勢と詳細形状の同時推定
近年のスポーツ映像配信やライブ映像配信では,視聴者が好きな角度から映像を楽しむことができる,自由視点映像技術が広く利用されている.こうした技術では多数のカメラにより得られた画像の解析が必要とされるが,近年では,単一視点画像からでも人物の3次元形状や姿勢を復元することで,より簡便に自由視点映像を作成する研究が行われている.しかし,単視点映像には奥行きの情報が含まれていないため,3次元復元に必要な情報を十分に得ることができない.
そこで本研究では,運動する人物を撮影し時系列画像情報を解析することで,,時刻ごとの姿勢と対象の詳細な3次元形状を同時に推定する方法を提案する.
そのために,人体の姿勢・形状の汎化モデルであるSMPLをより詳細な形状情報を表現可能な方法として拡張する.これを、微分可能レンダリングを用いて最適化することで,各時刻における姿勢と人物の概形だけでなく,髪型や服装といった詳細な形状を同時に復元する方法を示す.
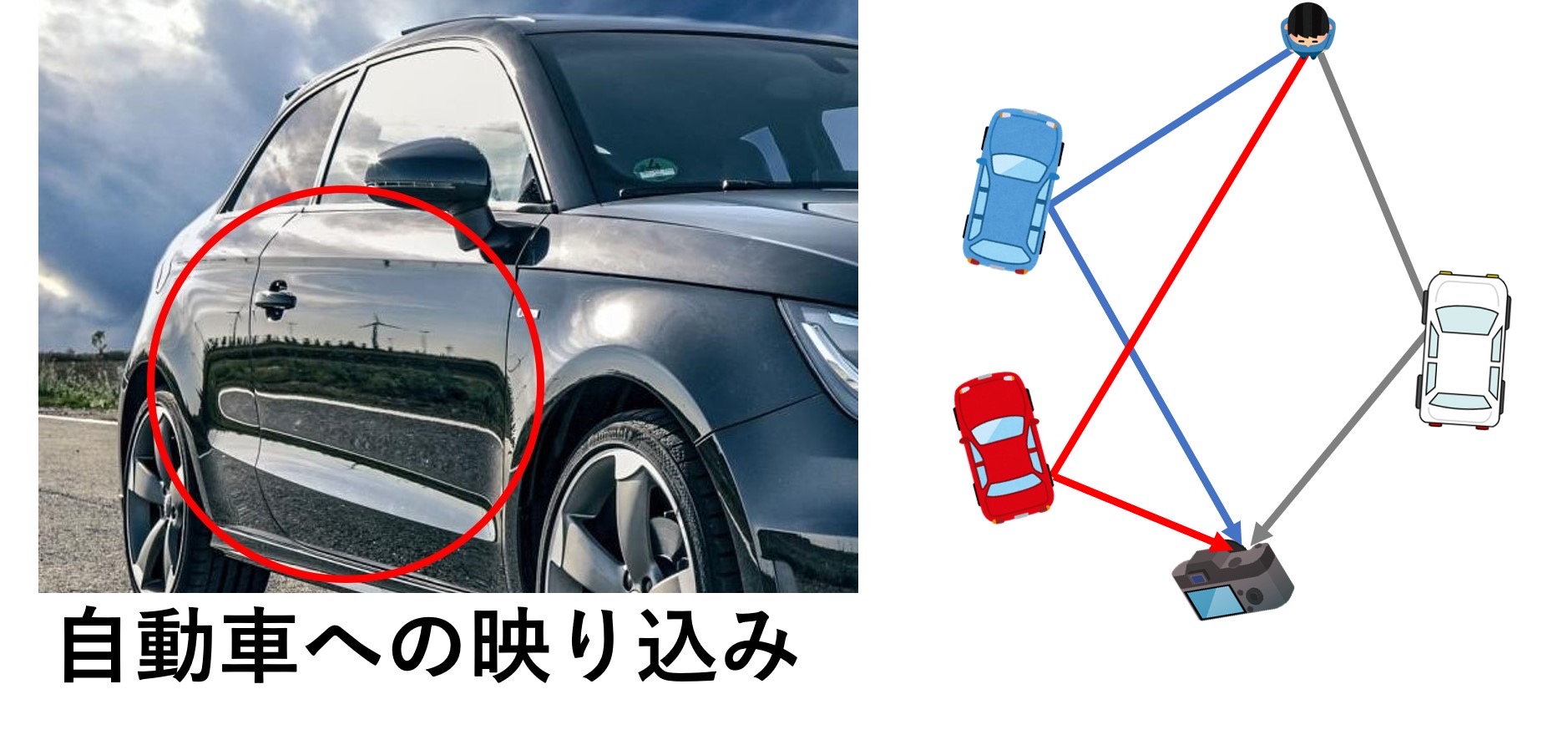
未知物体上の映り込みを用いた隠れた物体の3次元復元
近年,自動運転技術や運転支援技術などの様々な技術が開発されています.その効果もあり交通事故件数は年々減少しています.しかし,観測可能な領域の外,いわゆる死角については観測を行うことができず,そこからの飛び出しによる事故は多く発生しています.そのため,ドライバーの死角に存在する物体を観測・復元することが出来れば,このような事故を減少されられると考えられます.
そこで本研究では,道路上に多数存在する他車両のボディに着目し,そこから死角の観測を行う方法を提案します.一般的に,自動車のボディは鏡面として近似可能な材質により構成されており,そこに,様々な周辺の情景が写りこんでいます.
この情報を活用すれば,ドライバーが直接観測できない箇所の観測も可能となり,これにより死角を減らすことができます.本研究では,このような車両への映り込みを利用して,死角に存在する物体の情報と車両が写り込みを発生させている車両の情報を同時に復元する方法について検討を行っています.
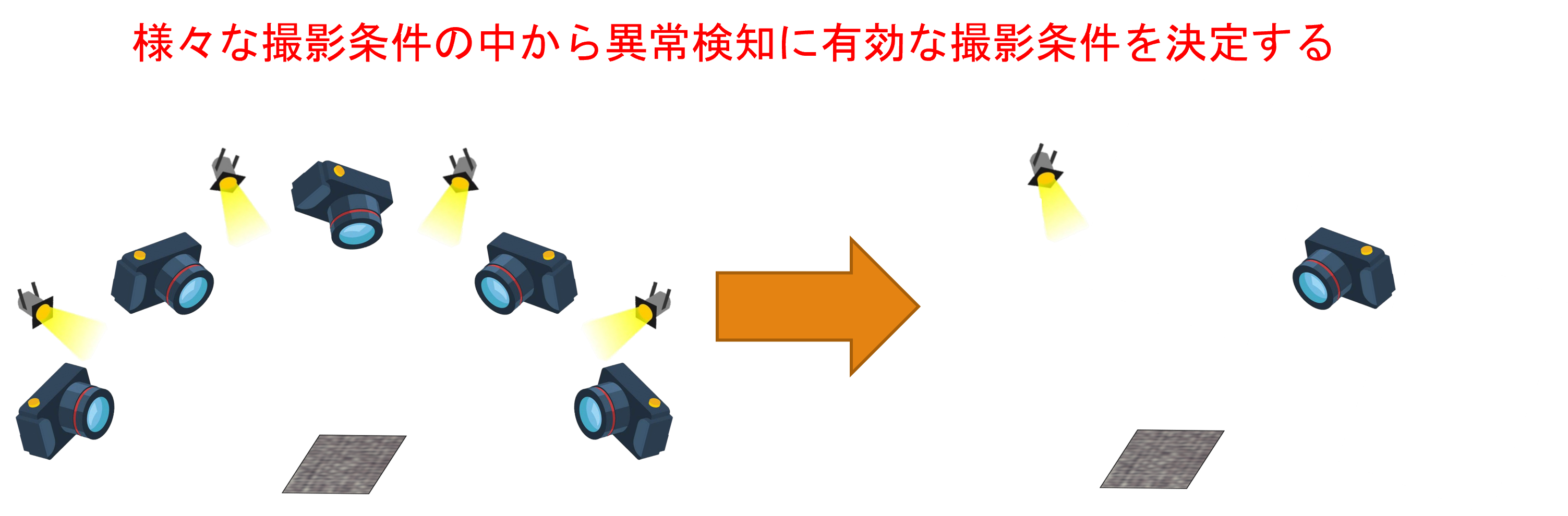
深層学習に基づく繊維製品の異常検知のための撮影最適化
近年,AI技術の発展に伴って製品の品質検査が自動化されています.しかし,細かな糸の集合である繊維製品は一般的な工業製品に比べてその複雑性が非常に大きく,実用的な自動異常検知は発展途上であるといえます.そのため,本研究では繊維製品におけるAIによる自動異常検知を目指して検討を行っています.
ここで,繊維製品の見え方が観測方向や照明方向によって変化することを考えると,様々な照明条件・撮影方向により多様な画像を撮影すれば,高精度な異常検知を実現可能と考えられます.しかし,この方法では検査に必要な撮影回数や画像枚数が非常に多くなるため,多くの時間的・金銭的コストがかかってしまいます.
そこで本研究では,画像を大量に撮影するのではなく,できる限り少ない撮影数でも異常検知が行えるような撮影方法の最適化を検討します.この方法により様々な撮影条件の中から異常検知に有効な撮影条件を自動的に決定することで,少ない画像からでも高精度な検査を実現することができます.
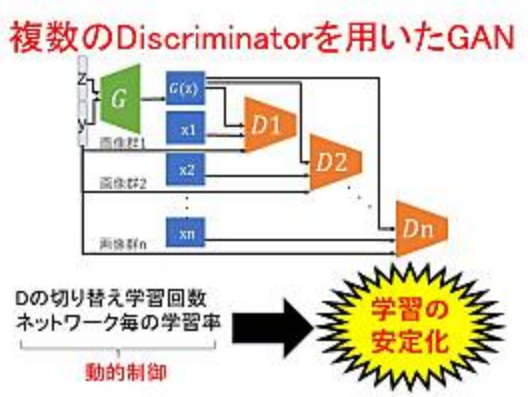
敵対的学習における複数Discriminatorの学習の安定化
本研究では,敵対的学習における複数Discriminatorの学習を安定化させる手法を提案します.
近年,深層学習ではGANと呼ばれる敵対的学習に基づく画像生成手法が注目を集めています.GANでは通常1つのGenerator(生成器)に対して1つのDiscriminator(識別器)で学習を行いますが,
本研究では1つのGeneratorに対して複数のDiscriminatorを用いて学習を行います.
この様にする事で,Generatorはより精度の高い画像を生成出来る様になります.しかし,複数のDiscriminatorを扱う学習では,Discriminatorの切り替えタイミングを適切に設定する事やDiscriminator間の学習バランスを均等に保つ事が非常に難しくなります.
そこで本研究では,適切なDiscriminatorの切り替え学習回数を動的に制御し,さらにDiscriminator毎に適切な学習率を動的に制御する事で,学習を安定化させる手法を提案します.
これにより,Discriminator の数を増加した場合でも適切な学習バランスを保つことが可能となり,高性能な Generator
を安定に学習することが可能となります.
論文からのプレゼンテーション資料の自動生成
研究発表においては,論文を公表するだけでなくプレゼンテーション資料を用いた発表が実施されます.
そのため,自身の研究を学会において効果的に伝えるためには,プレゼンテーション資料の良し悪しが重要な要素となります.しかし、優れたプレゼンテーション資料を作成するためには,経験やセンスが必要となってきます.そのため,プレゼンテーション資料の作成経験が浅い研究者にとって,優れたプレゼンテーション資料を作成することは困難です.
そこで本研究では,入力された学術論文から,スライド構成を自動生成すると共に,スライドで用いる図や文字を学術論文から自動抽出し,これらを基にスライド画像を自動生成する手法を研究しています.この手法により,論文の内容に即した優れたプレゼンテーション資料の完全な自動生成の実現を目指しています.
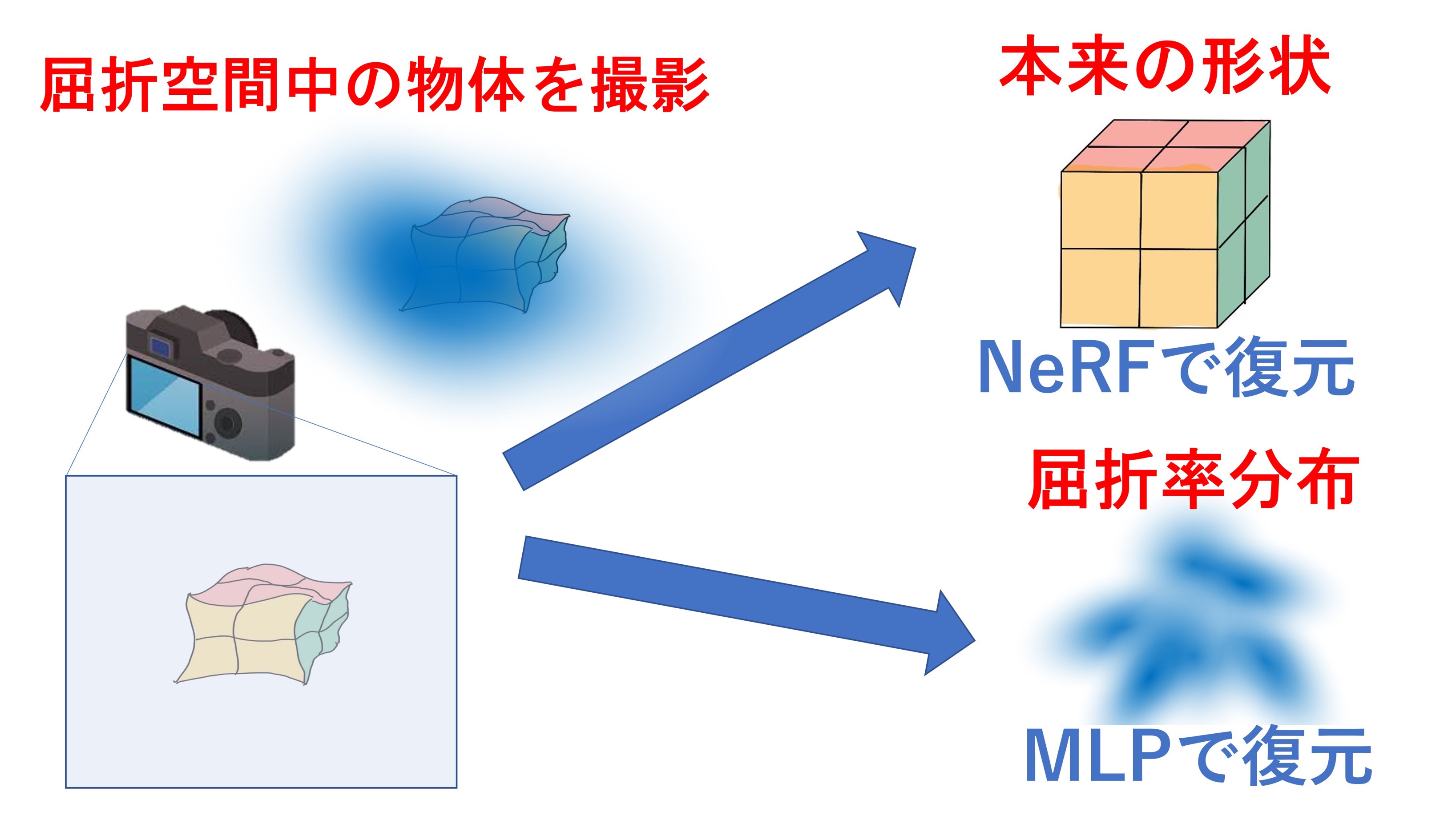
光線の歪みを考慮したNeRFによる空間構造とシーン形状の同時3次元復元
本研究では,不均一な屈折媒体で満たされたシーンにおいて、屈折率の分布とシーンの形状を同時に復元する方法を提案している.これにより,従来の3次元復元手法では表現できなかった,光が曲がりながら進むようなシーンに対しても様々なビジョン技術を適用可能となる.
これまでに提案されたほぼすべての3次元計測法は,光が3次元空間中を直進することを前提に組み立てられている.しかし実際には,陽炎のように,光が屈折しながら進む状況は身近なシーンにおいてもに数多く存在している.そのため従来の3次元復元手法では,光が曲がりながら進むこのようなシーンを表現・復元することができなかった.
そこで本研究では,屈折の状況とシーンの3次元情報を同時に復元する方法を提案し,新しいビジョン技術の確立を目指す.
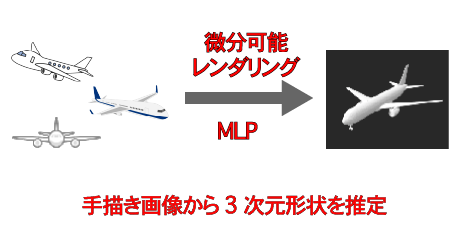
手描き画像からの曖昧性を含む3次元形状復元
本研究では,NNを利用した3次元形状表現を用いて,手書き画像から3次元形状情報を復元する方法について検討を行う.
近年、3Dモデルの需要の高まりにより、様々な3次元形状の復元方法が提案されている。しかし、従来の3次元復元手法では、それぞれの視点で観測した画像がかならず一意の形状を表現している,すなわち,整合している画像の利用を前提としている.そのため,このような条件が満たされないイラストなどの手描き画像からの3次元復元に適用することができなかった。
そこで本研究では、手書き画像に含まれる曖昧さを3次元形状の変形とみなし,この変形と変形前の形状を同時に復元することで,手書き画像からの3次元復元を実現する方法について検討を行う.
偏光の特性を利用した散乱媒体の解析
本研究では,散乱媒体中にある物体の情報を取得するために,得られる観測光から物体の拡散反射光を分離する手法を提案しています.
近年IoTや画像情報処理技術の発展によって様々なシーンでカメラが使用されますが,屋外での撮影においてシーンが霧や雨滴などの散乱媒体で満たされることは往々にして発生します.このようなとき,周囲の状況は不明瞭となり,適切な画像を取得することは困難になります.そこで,散乱媒体におる光の散乱の影響を抑制する観測法が求められています.
本研究では,光の散乱や反射によって偏光状態が変化するという偏光の特性を利用します.偏光カメラによって偏光を観測するだけでなく,光源側にも偏光板を取り付けて回転させることでシーンに照射する偏光を変化させます.これによって観測する偏光状態の変化について動的な調整を行い,適切な物体拡散反射光を分離する方法について検討しています.
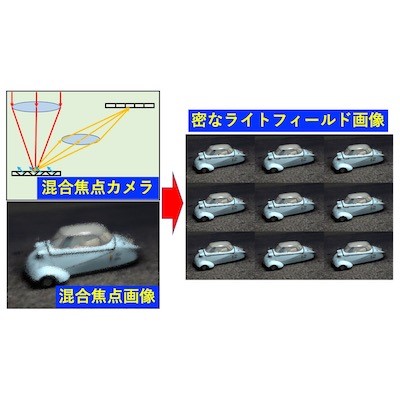
混合焦点カメラを用いた高密度なライトフィールド撮影
近年の映像コンテンツの流行により高品質な映像情報への要求が高まっており,これに伴い更なる高品質な映像が求められています.映像の高品質化には撮像技術の向上や編集技
術の向上などが必要となりますが,撮像技術の中でも特にライトフィールドを撮影する技 術が注目を浴びています.
一般的な撮影方法では,シーン中に存在する対象物体などから発せられた光線を積分することで 2
次元画像が撮影されますが,ライトフィールド撮影では,光線の状態をそのまま記録することで,多くの情報を取得できます.この情報は 4
次元情報であることから,非常に大きなデータとなります.
本研究では,ライトフィールドの情報量を考慮した,効率的なライトフィールドの取得,及び取得した情報から元の4次元ライトフィールドを復元することを目的とし,効率的なラ
イトフィールド取得方法,及び表現方法を提案することで,画素数の少ないカメラでも密なライトフィールドを取得することを研究しています.
【関連発表】
廣瀬 正人, 坂上 文彦,佐藤 淳
“混合焦点カメラを用いた高密度なライトフィールド撮影”
第25回 画像の認識・理解シンポジウム(MIRU2022),IS1-1
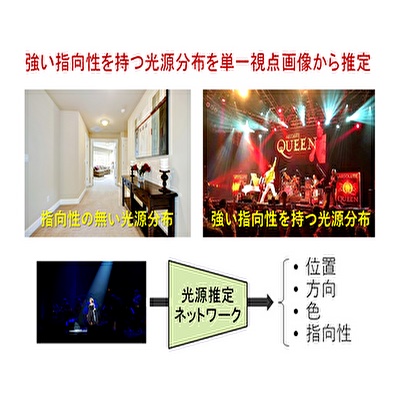
光の散乱を用いた強い指向性を持つ光源分布の推定
本研究では,音楽ライブで用いられるスポットライトのような強い指向性を持つ光源の分布を推定する手法について研究を行っています.
画像情報から光源の分布を推定することは拡張現実の実現などにおいて非常に重要であり,近年では,シーン全体の光源を推定する光源分布推定法が広く提案されています.しかし,これまでの光源分布推定法では,各光源が指向性を持たないことを仮定し,推定が行われていました.一方,音楽ライブなどでは,方向ごとに色や明るさが異なる強い指向性を持つ光源が多数用いられており,このようなシーンに対してこれらの方法を適用することはできません.
そこで本研究では,このような強い指向性を持つ光源分布を,単一視点画像から推定する手法を検討しています.提案法では,強い指向性を持った光源を,各光源の位置・方向・色・指向性のパラメータを用いて表現し,それらのパラメータを深層学習を用いて推定します.これにより,これまでの方法では推定が難しかったシーンについても,光源分布情報を推定することが可能となっています.
【関連発表】
伊與田幸介, 坂上文彦, 佐藤淳
"光の散乱を用いた強い指向性を持つ光源分布の推定"
第28回 画像センシングシンポジウム(SSII2022),IS2-28
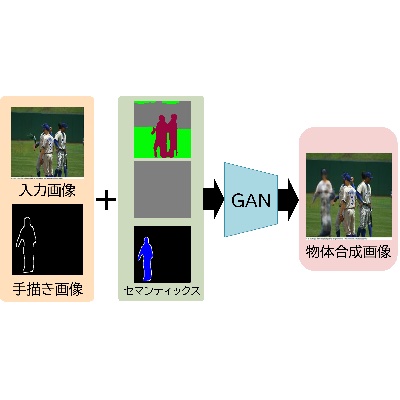
セマンティック情報に基づくシーンに適合した物体の手書き合成
本研究では深層学習によるシーンに適合した物体の画像合成をする研究を行っています.
自然な画像加工を行う場合には,素材となる画像コンテンツの不足や高度な画像編集技術が必要となるなどの問題があります.
そこで本研究では深層学習ネットワークの一種であるGANを用いて,既に存在する画像に対して合成したい物体の簡単な外形を手で描き入れるだけで,画像のシーンに適合した自然な物体を自動合成する手法を提案しています.具体的には画像中の物体のセマンティックラベルやシーン情報,物体情報などの高次な情報を解析して用いることにより,シーンにより適合した画像の生成を行います.
【関連発表】
鬼頭俊一, 坂上文彦, 佐藤淳
"セマンティック情報に基づくシーンに適合した物体の手書き合成"
第25回 画像の認識・理解シンポジウム(MIRU2022),IS2-50
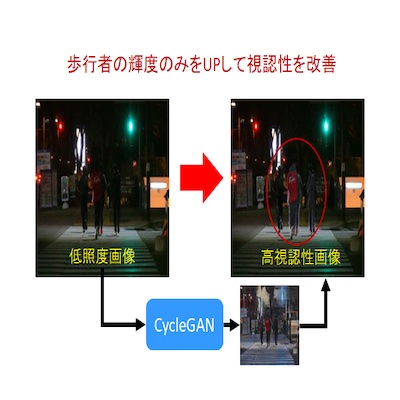
深層学習による夜間の歩行者の視認性改善
本研究では,夜間の自動車対歩行者の交通事故を防ぐための画像生成手法について検討を行っています.
近年,完全自動運転に向けた技術研究が活発に行われていますが,夜間に運転を行う場合,自動・手動に関わらずその安全性が低下することが知られています.これは,夜間に撮影された映像においては,歩行者が背景と同化してしまいその認識が困難になるためです.本研究では,この問題を解決するための画像生成手法を研究しています.この方法では,夜間の低照度下で撮影された画像から,深層学習を用いて昼間に撮影したような鮮明な高輝度画像を生成し,歩行者のみを高輝度画像に置き換えます.これにより,左図のような歩行者の視認性を大幅に改善することが可能です.
本研究では,この技術を実現するために,様々なカメラで撮影されたペアの無い昼と夜の画像からなるデータセット作成しました.さらに、このようなデータセットを用いて学習を行うことで,様々な異なるカメラにおいて歩行者の視認性を向上させられることを確認しています.
【関連発表】
小島のどか, 坂上文彦, 佐藤淳
"深層学習による夜間の歩行者の視認性改善"
第28回 画像センシングシンポジウム(SSII2022),IS2-04
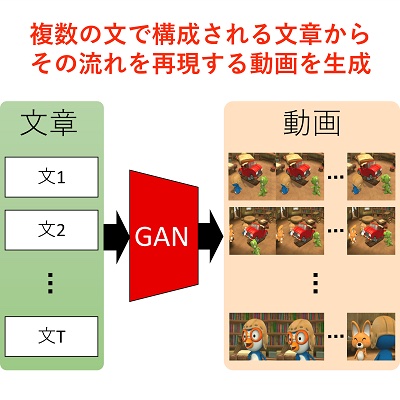
複数の文よりなる文章からの動画生成
本研究では,深層学習を用いて,複数の文で構成される文章からその流れを再現する動画を生成する研究を行っています.
近年,深層学習の研究の発展により,様々な入力情報を画像や動画へ変換することが可能になってきています.その研究の一つとして,テキストデータを動画へ変換する方法が提案されています.しかし,従来のテキストデータからの動画生成は,入力として用いられる文は1文のみであり,文章から動画を生成することはできませんでした.
そこで本研究では,ディープニューラルネットワークの一種であり,画像生成分野においてよく用いられているGANを利用することで,文章からその流れを再現する長尺の動画を生成する方法を検討しています.この研究によって,小説や脚本などの長文からの動画生成が可能になると考えられます.
【関連発表】
神崎宇弘, 坂上文彦, 佐藤淳
"複数の文よりなる文章からの動画生成"
第25回 画像の認識・理解シンポジウム(MIRU2022),IS3-58
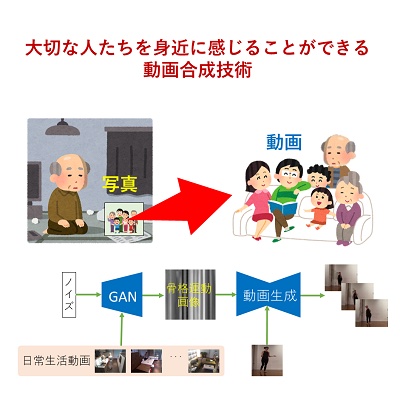
敵対的学習による日常生活の自動生成
昨今,コロナウイルス感染症の万円などの影響などにより,家族と離れて暮らす人が増えています.それに伴い,孤独を感じる高齢者などが増加していると言われています.そこで本研究では,写真の中の人物に対してその人らしい動きを与えることで,遠く離れた場所にいる大切な人が身近に存在するように感じることができる動画合成技術の実現を目指しています.
これと類似する技術として,近年,静止画の人物に対して別の人物が行った動きを与える手法が提案されています.しかし,それらの手法では,元となる動きを別の人物が与える必要があるため,静止画の人物に対してその人物らしい動きを自動生成することはできません.
そこで本研究では,GANと呼ばれるニューラルネットワークのフレームワークを用いて,その人物らしい生活行動をノイズからランダムに生成するよう学習を行います.このとき,実際の様々な生活行動と類似した動きを生成するよう学習を行うことで,入力として特定の動きを与えずに,ノイズからその人物の動きの特徴を持った様々な生活行動を自動生成することが可能となり,よりその人らしい動画像の生成が可能となります.
【関連発表】
熊谷美紀, 坂上文彦, 佐藤淳
"敵対的学習による日常生活の自動生成"
第28回 画像センシングシンポジウム(SSII2022),IS3-28
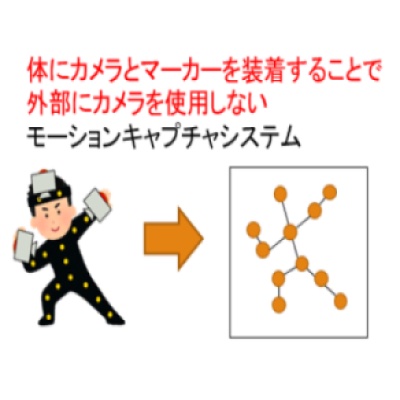
非同期カメラの相互投影を利用した自己装着型モーションキャプチャシステムの検討
本研究では,非同期カメラの相互投影を利用することで,場所の制約を受けない小規模なシステムで人体の形状復元を行う方法について検討しています.
近年,人の動きを計測し数値化するモーションキャプチャの技術が様々な分野で研究されており,今後も広い分野で応用されていくことが予測されます.しかし,現在主流のモーションキャプチャ方法である光学式は計測精度が高い一方で,撮影範囲の周囲にカメラを設置する必要があるためシステムが大規模になりやすい問題があります.
そこで本研究では,撮影のためのカメラを人体上に装着した自己装着型モーションキャプチャに注目し,装着したカメラ同士が互いを撮影している相互投影の際に成り立つ幾何を利用することによって,小規模で安定な3次元復元の実現を目指しています.
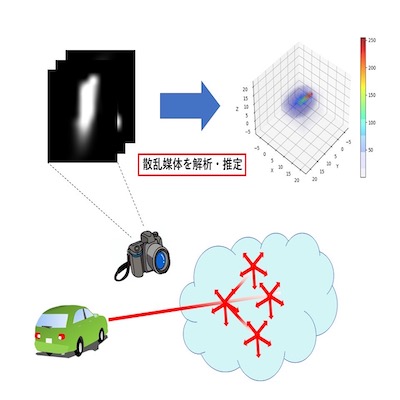
不均一な散乱媒体の物理的な特性を考慮したR-CNNによる表現
本研究では,霧や煙などの散乱媒体で満たされたシーンについて,R-CNNと呼ばれるニューラルネットを利用して解析を行っています.近年,自動車にはカメラが搭載されており,それによって周辺環境の情報を取得しています.しかし,散乱媒体がある道路では,情報の取得が困難になってしまいます.
そのような状況に対応するために,本研究では,車のライトなどの光線が霧に投影される状況を想定して,散乱媒体に光線を投影し,その投影結果を撮影することで,媒体の特性を計測し,その特性から散乱媒体を表現することを目的としています.散乱は散乱媒体内に入射した光線が媒体内の粒子と繰り返し衝突し起こる現象で,従来の研究により畳み込みで表現可能です.
本研究では,散乱の畳み込み部分をCNN,繰り返し部分をリカレントとすることによって,複雑な散乱をR-CNNで表現します.この技術によって,霧がある道路での自動運転の安全性が向上すると考えています.