Recovering 3D structure of nonuniform refractive objects

In this research, we study a method for recovering the whole 3D structure in space by observing the bending of light.
In computer vision, research has been conducted on the premise that light travels straight. However light actually bends as it travels in the 3D space.The phenomenon of light bending occurs frequently in our daily lives. For example, when we look on the road on a hot summer day, we may see heat haze. This is caused by the light being bent because of the nonuniform refractive index of the air.
In this research, we are studying the method to estimate the three-dimensional refractive index distribution of the whole space based on such a curve of light.The refractive index distribution obtained in this study represents the very nature of the object in the space, so it can be considered equivalent to recovering the 3D structure of the entire space. This makes it possible to visualize things that could not be observed with conventional imaging methods, such as the fine structure inside cells and the degree of agitation of colorless and transparent chemicals.
<< MIRU Nagao Prize >>
Encrypted image presentation using 5D light field display
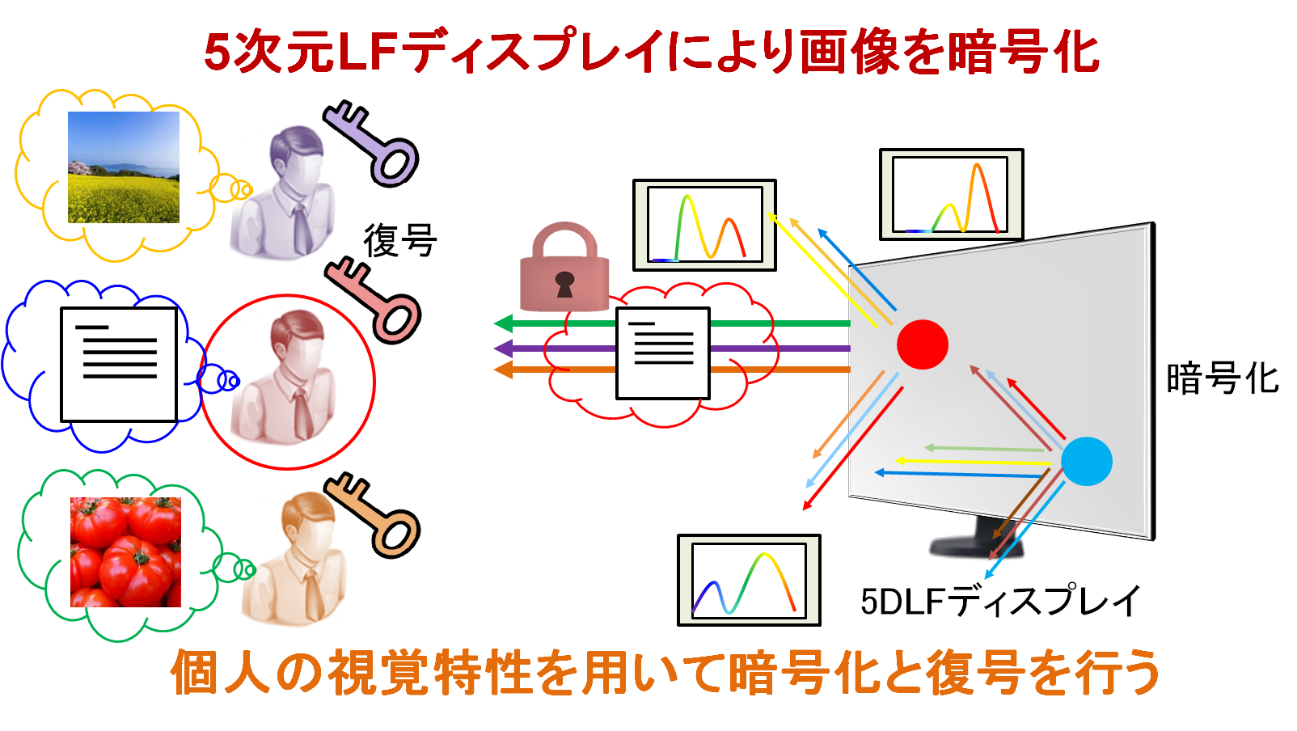
In this research, we study a method for presenting encrypted images to human vision directly by using 5 dimensional light field display.
In the information society in recent years, the importance of encrypting information is increasing from the viewpoint of protection of privacy and secrecy of important information, and encryption technology in communication is actively studied. However, no matter what type of encryption technology is used, the decoded information must be displayed on the display for the user to see the information, and other people can see the information by peeping.
Therefore, in this research, in order to prevent such leakage of information, we are studying a display method that only a specific user can observe. In this method, the information sent is displayed as an encrypted image that can be decrypted only by the user's visual characteristics, so that information leakage due to peeping is prevented. In order to realize such information presentation, we are developing a special device called light field display. By using our technology, it becomes possible to realize secure information presentation without reducing the convenience at the time of use.
Image transformation GAN based on selective learning of discriminator

In this research, we are examining the method of generating summer road image from snow road image by using GAN which is a kind of deep neural network.
In recent years, GAN has attracted attention as one of the methods for generating images. GAN consists of a generator called Image Generator and a network called Discriminator for judging the validity of the generated image. By learning and growing these two at the same time, the image is more accurate than when using a conventional deep neural network. You can do generation.
GAN like this converges to a state in which the Generator and the Discriminator do not proceed with further learning, which is called the Nash equilibrium, if the learning is stable. Therefore, it is important for Generator and Discriminator to acquire high ability at the time of Nash equilibrium, in order to perform more accurate image generation. Therefore, in this research, multiple Discriminators are prepared for one Generator, and Discriminator's discrimination ability is enhanced by making each Discriminator selectively learn different specialized fields. As a result, it is possible to improve the convergence state at the time of Nash equilibrium to a more accurate one, and as a result, it is possible to enhance the image generation capability of the Generator.
Simultaneous recovery of 3D shape and high resolution images from multimodal images
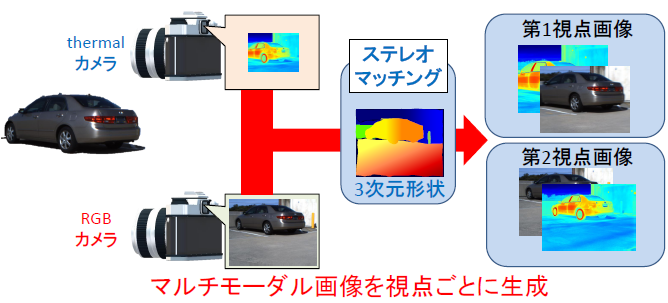
In this research, by combining cameras with different properties (modal) placed at different viewpoints, we measure the three-dimensional shape of the input scene and consider a method to acquire multimodal images taken from a single viewpoint.
In recent years, various modal cameras such as thermal cameras used for surveillance cameras at night and IR cameras used for in-vehicle cameras etc. are widely used. However, although the shooting modal required for each use scene changes, it is difficult to obtain all modal information with a single camera. Moreover, in recent systems, not only image information but also information on the distance to the target is used in a very large number of scenes, and a system capable of acquiring these simultaneously is required.
Therefore, in this research, we aim to develop a camera system that can measure distances with various characteristics. As an approach for that purpose, we are researching a method to simultaneously perform 3D shape measurement and multimodal image generation by applying special stereo matching to stereo images taken by cameras with different viewpoints and different modals. . By using such a method, it is possible to construct a general-purpose camera system that can easily obtain the necessary information without using a special and effective camera.
Simultaneous recovery of background scenes and water surface shapes under heavy rain
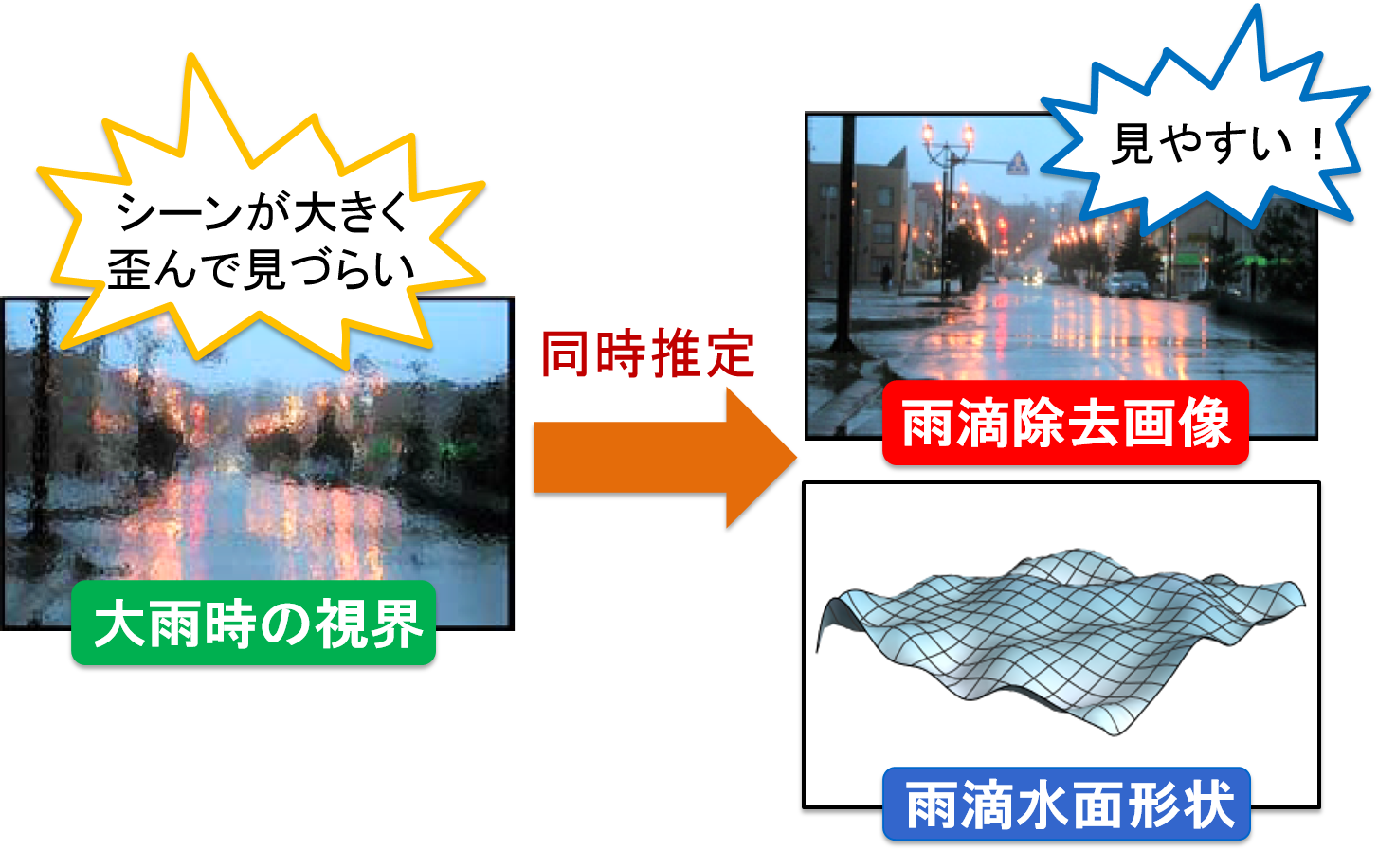
In this study, we are examining the method to generate the image which removed distortion by raindrops from the image distorted by a large amount of raindrops.
When driving in rainy weather, raindrops adhere to the windshield and interfere with visibility, which increases the risk of an accident. In order to solve this problem, a method has been proposed to remove raindrops from in-vehicle camera images by image processing. However, in the conventional method, it was assumed that the amount of raindrops attached to the windshield was relatively small, and the background scene could be observed from the gaps of the raindrops. For this reason, there is a problem that raindrops can not be removed correctly if the raindrops spread like a film over the entire area of the windshield in heavy rain such as guerrilla heavy rain which is increasing trend in recent years.
Therefore, in this research, by expressing the entire surface of the windshield including raindrops as a curved surface, we developed a method that can handle even large amounts of raindrops. In addition, by analyzing images taken through such a curved surface, we are studying a method to realize simultaneous generation of a curved surface shape including raindrops and an image without raindrops.
Generation of an anti-reflection image in an in-vehicle camera
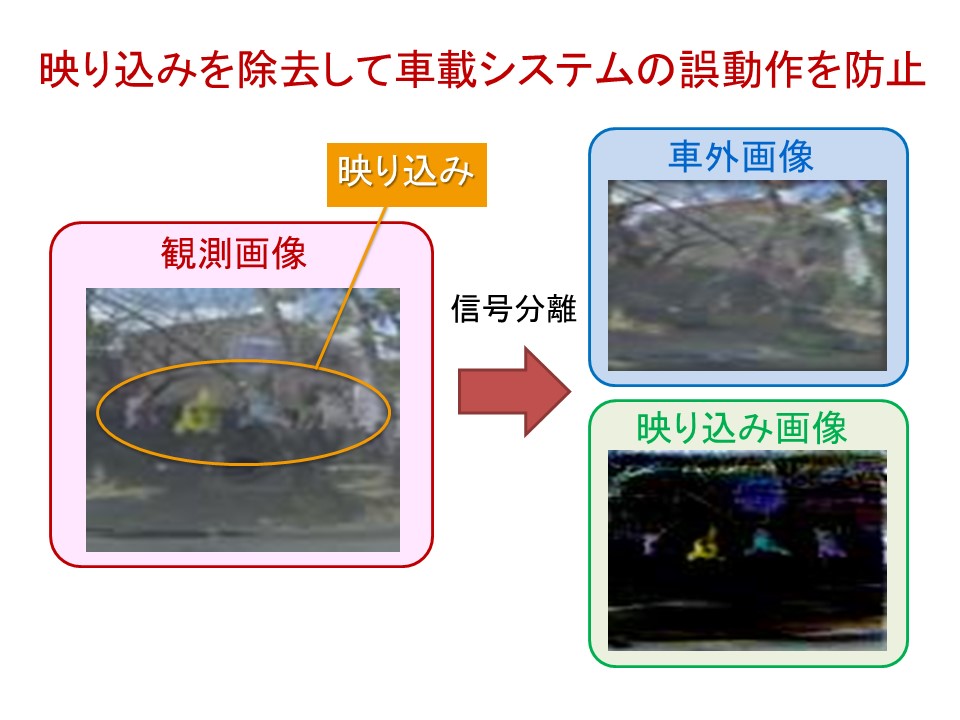
In this research, we propose a technology that generates an image that separates an external scene from a reflection on a glass surface by analyzing an image in which a glass surface and an outside scene are simultaneously captured, such as an on-vehicle camera image of a car.
Generally, in an image taken with a car-mounted camera, the light striking the dashboard is reflected by the windshield to be incident on the camera, so the photographed image is an object in the car interior reflected in the glass surface and the scene outside the car Will be taken at the same time. If such a reflection image is directly input to a collision detection system etc., the reflection part may be misrecognized as an object in front of the runway, which may lead to a serious accident such as a malfunction of the brake.
In this research, a method is used to separate the image from the light incident from the outside of the vehicle and the reflected image from the inside of the vehicle using the property that the in-vehicle camera is fixed in the vehicle compartment and does not move relative to the vehicle. Are considering. As a result, it becomes possible to supply an image from which reflections have been removed to an in-vehicle system etc., and it is considered that a high-accuracy image recognition system with reduced false recognition can be realized.
3D driving scene prediction using in-vehicle stereo camera and GPS
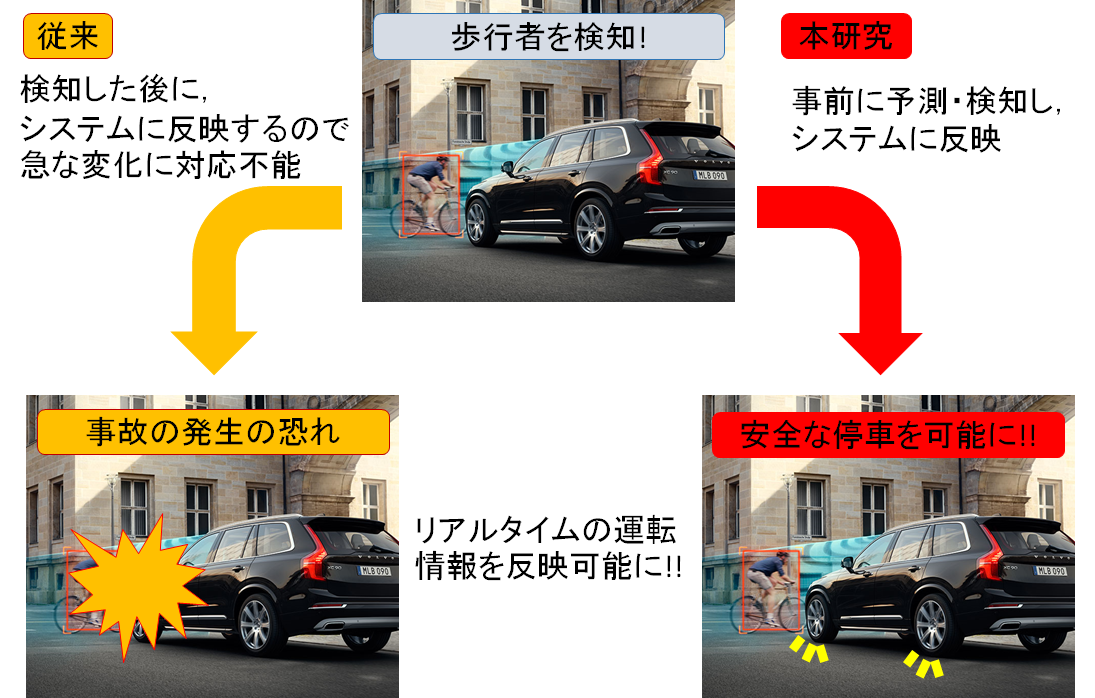
In this research, we consider a system that predicts the future driving scene at the time of driving by using various in-vehicle sensor information.
In recent years, research on technologies related to vehicle control, such as automatic driving and driving support, has been actively conducted. Generally in such technology, various information is acquired by using multiple in-vehicle sensors, and various processing is performed based on the information. However, it takes a certain processing time to acquire and analyze information from in-vehicle sensors. Therefore, the information used to control the vehicle is in the past for a certain period of time, making it difficult to cope with sudden scene changes such as jumping out.
Therefore, in this research, we focus on the information obtained from the in-vehicle camera that plays a central role among the in-vehicle sensor information, and propose a method to predict the in-vehicle camera image. This makes it possible to reflect in-vehicle sensor information in real time even when using an automatic operation system that includes a delay, making it possible to configure a safer system.
Analysis of scattering media using ToF camera
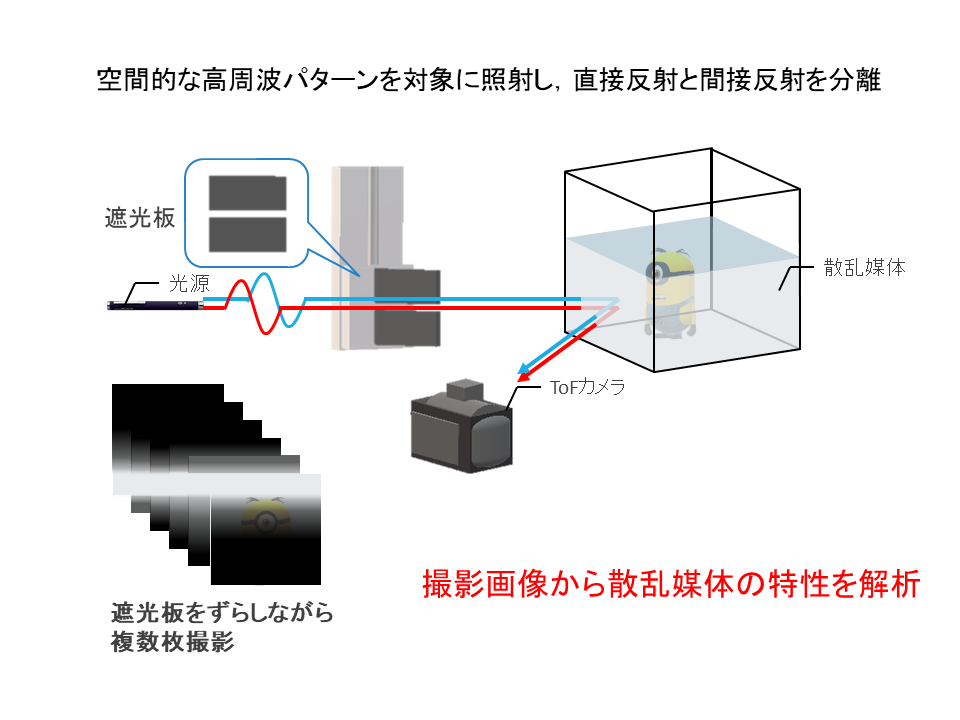
In this study, we will study how to analyze the characteristics of scattering media efficiently by projecting controlled special light beams onto the scattering media such as fog.
In recent years, a new information presentation technology has been proposed that presents three-dimensional information by performing light field projection on a scattering medium such as fog, etc. In such a technology, projection is performed according to the characteristics of the scattering medium to be the screen. You need to change the pattern. Since analysis of such characteristics requires a large number of projections and calculations to be repeated, there is a problem that projection is difficult for a medium in which the state of a natural fog or the like constantly changes.
So, in this research, we propose a method to analyze media efficiently by using ToF camera. In this method, by projecting temporally modulated light onto the scattering medium, not only the brightness of the ray but also the path through which the ray was observed are obtained directly. Furthermore, by analyzing such information, we are studying a method to analyze the scattering medium more stably than using only images observed by a general camera.
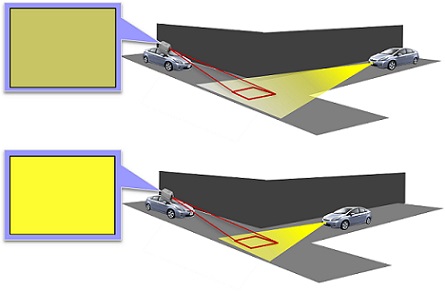
Driver vision assistance by incident light control

In this research, we are studying a system to reduce glare caused by backlighting when driving a car and headlights of oncoming cars.
In general, when a very bright object such as the sun or headlights enters the field of view, a dazzling phenomenon occurs in which the field of view disappears for a few seconds. If such a phenomenon occurs while driving, the visibility of the driver may deteriorate and the possibility of causing a traffic accident increases, which is very dangerous.
Therefore, in this research, we are studying how to adjust the amount of light observed by the driver to be constant by setting the transmissive liquid crystal in the driver's field of vision and controlling it. When performing such control, it is necessary to keep in mind not only the dazzling phenomenon suppression but also the original visibility, so in this study the overall brightness of the observed image and the local brightness Focusing on both, we have proposed a method to control the amount of incident light of high-intensity parts while maintaining the information of the details of the observation scene by controlling each appropriately. This makes it possible to suppress the strong light that causes the dazzling phenomenon while securing the visibility of the driver.
Calibration and 3D reconstruction in multi-view stereo camera using water droplet

In this study, we are examining a method to calibrate a multi-view stereo camera using water droplets and restore the 3D shape of a scene from a single shot image.
Conventional multi-view stereo cameras have the problem of being expensive and difficult to obtain compared to regular cameras, because they require special equipment such as a lens array. However, in this research, by constructing a multi-view stereo camera with only a general camera and water droplets, it is possible to restore the scene shape in three dimensions inexpensively and easily.
For this purpose, we focus on the point that each drop plays a role of a small lens in this research. As a result, it is possible to consider that an image taken with a lens to which water droplets are attached contains information from multiple viewpoints as well as an image taken with a lens array. In this research, we analyze the photographed image obtained through the water droplet, and consider the method to estimate the shape of the whole lens and the three-dimensional shape of the scene simultaneously.
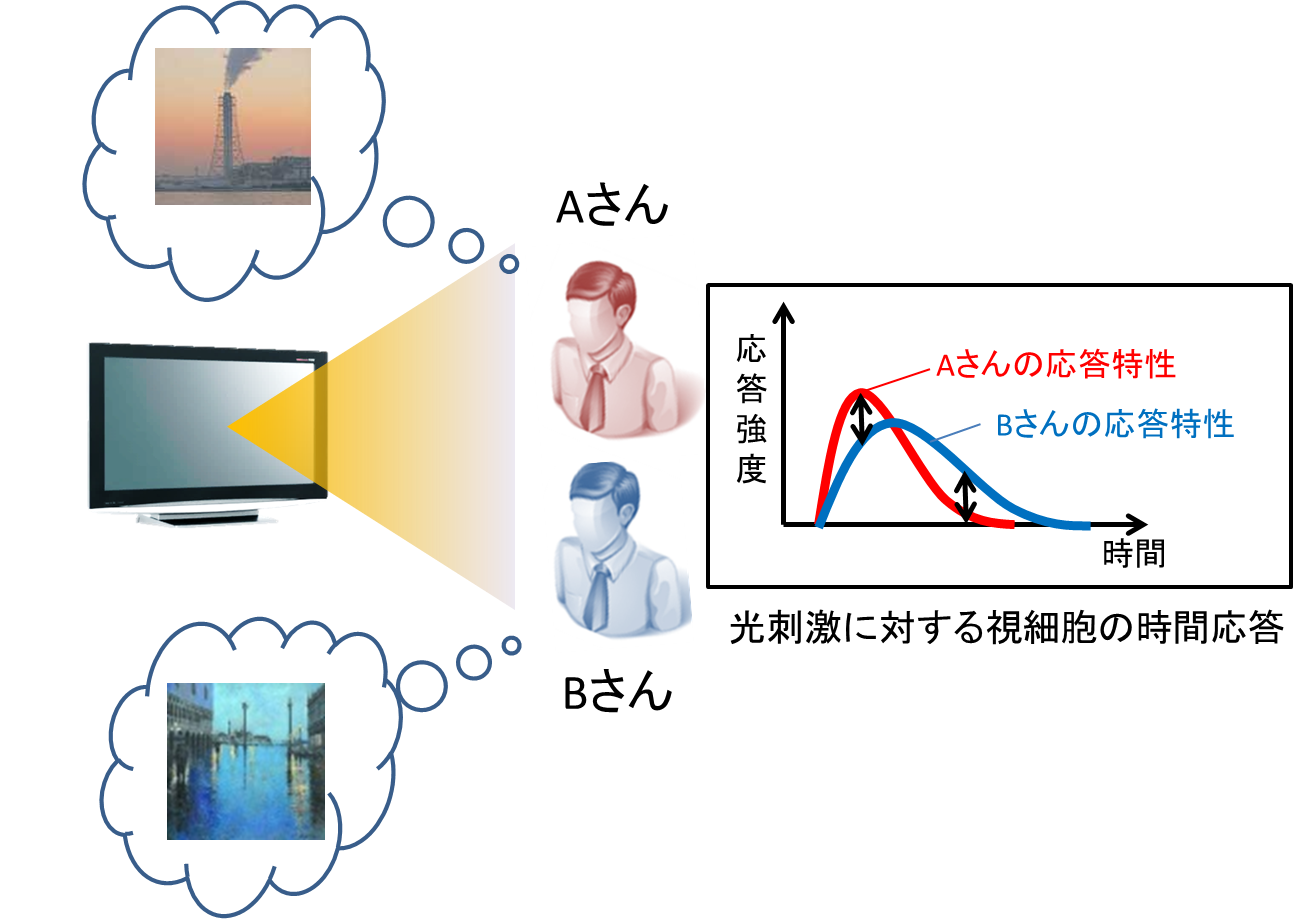
Accurate multiple image projection based on human spectral sensitivity characteristics and time response characteristics
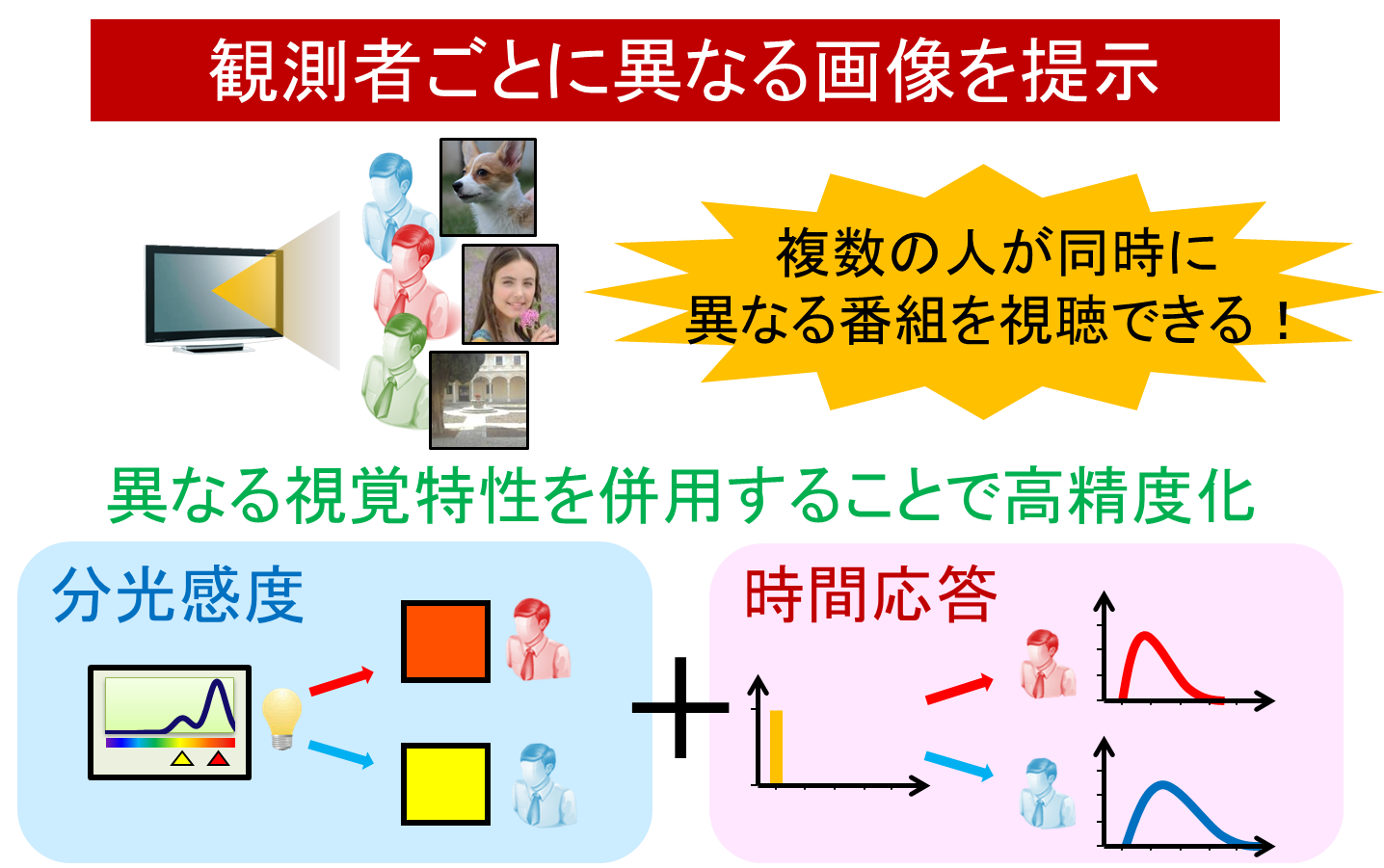
In this research, we are studying how to realize multiple image projection with higher accuracy by using the difference of human's multiple visual characteristics.
Multiple image projection is a technology that allows different viewers to observe different moving images by presenting only a single moving image. By applying this technology, multiple images can be displayed on one screen. It is possible to realize next-generation television etc. where people in can watch different programs simultaneously.
In this research, we focus on spectral sensitivity characteristics and time response characteristics among human visual characteristics. Spectral sensitivity characteristics are the response intensity of human photoreceptors to the wavelength of light, and it is known that there are differences among people. In addition, the time response characteristic indicates how the response intensity of photoreceptors changes with time when light enters the human eye, and there is a difference for each person as in the spectral sensitivity characteristic. It is known. Because of the individual differences between these two characteristics, even if the same light is observed simultaneously, it will be different photoreceptor response from person to person. In this research, by using this, it is possible to realize highly accurate multiple image projection which does not require special equipment and does not depend on the observation position.
High precision image deblurring by passive coding exposure
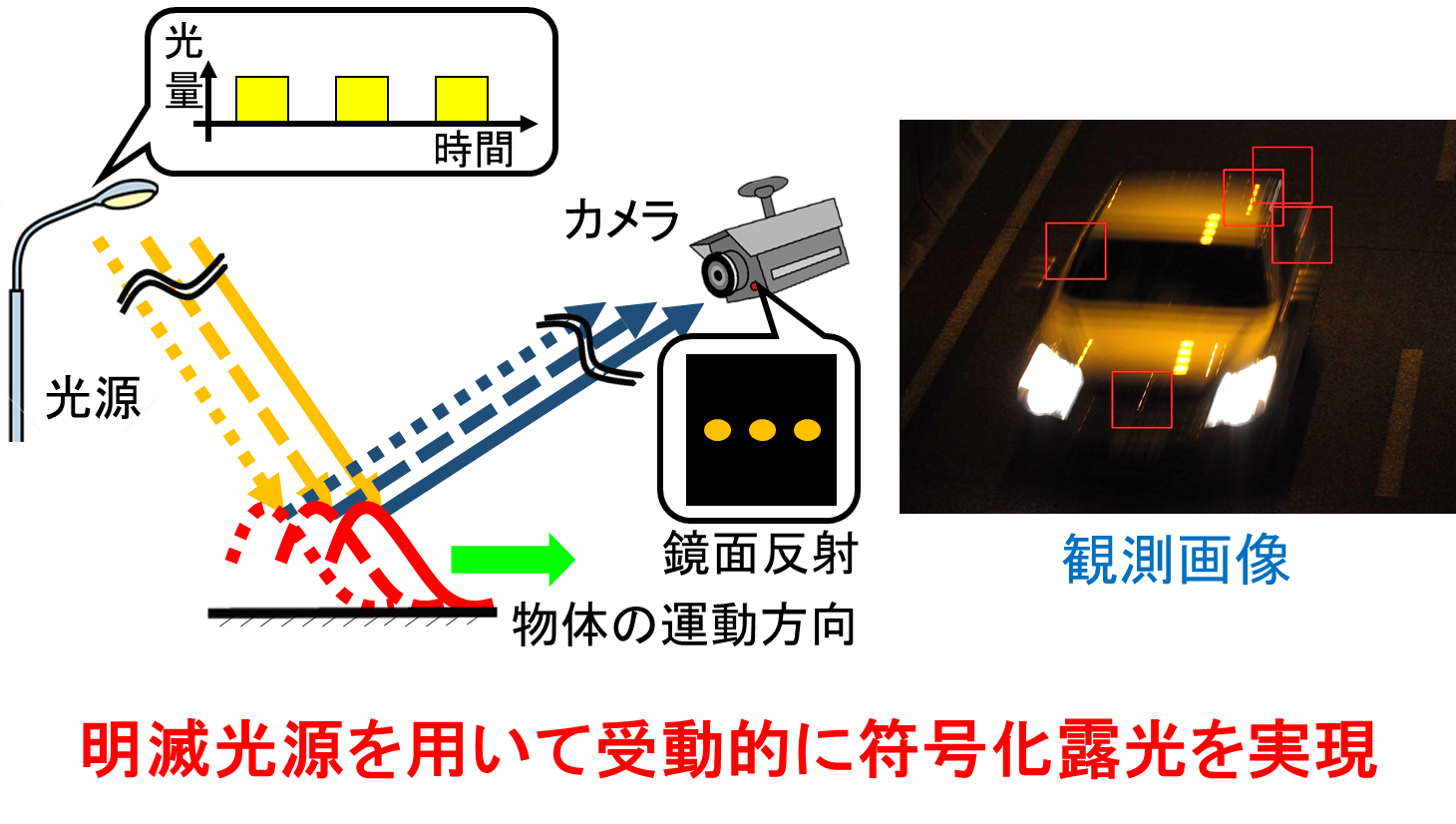
In this research, in order to restore the image with high precision, we are studying the method to realize the coded exposure using only the normal camera under the general environment.
In recent years, coded exposure of images has attracted attention as one of the methods to restore clear images from blurred images. In coding exposure, stable blurring restoration can be realized by controlling the temporal coding of the shutter opening and closing and the blinking of the light source that illuminates the object, and improving the frequency characteristic of the image blurring. However, there is a problem that it is expensive because it requires a camera and lighting with a special encoding function, and it is difficult to apply it to a camera that has already been installed.
In this research, it is possible to encode the exposure passively only with a normal camera by using a blinking light source such as a fluorescent lamp or an LED which is abundant in our living environment, without using a special camera. It will be possible.
Three-dimensional video presentation by light field projection on diffusion media
In this research, we develop a new device, a light field projector and a 3D diffusion screen, and examine how to draw a 3D object directly in space using them.
A light field projector is a special type of projector that projects an arbitrary light space (light field) in the target space, and is used for the projection of images that can be viewed stereoscopically. By projecting the light field onto a special 3D screen called a 3D diffusion screen, it is possible to project any 3D object.
In this research, we consider how to create a light field for presenting a three-dimensional image by modeling the spread of light on a diffusion screen using a point spread function (PSF).
Multiple image projection using differences in time response of photoreceptors
By using differences in human visual characteristics, we are researching to have multiple people simultaneously observe different images with a single image.
When a human photoreceptor receives a light stimulus, the response to it lasts for a certain period of time. Therefore, the stimulus that human beings observe at a certain time is also influenced by the stimulus received in the past. Also, since this response varies from person to person, the observed stimuli will differ from person to person even when observing the same continuous light signal. This is used to realize different images for different people. As a result, in this research, it becomes possible to present information independent of the observation position without mounting a special device.
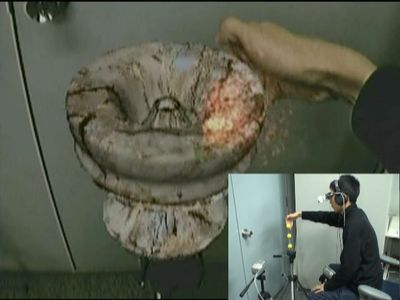
Measurement of visual acuity characteristics using a light field display
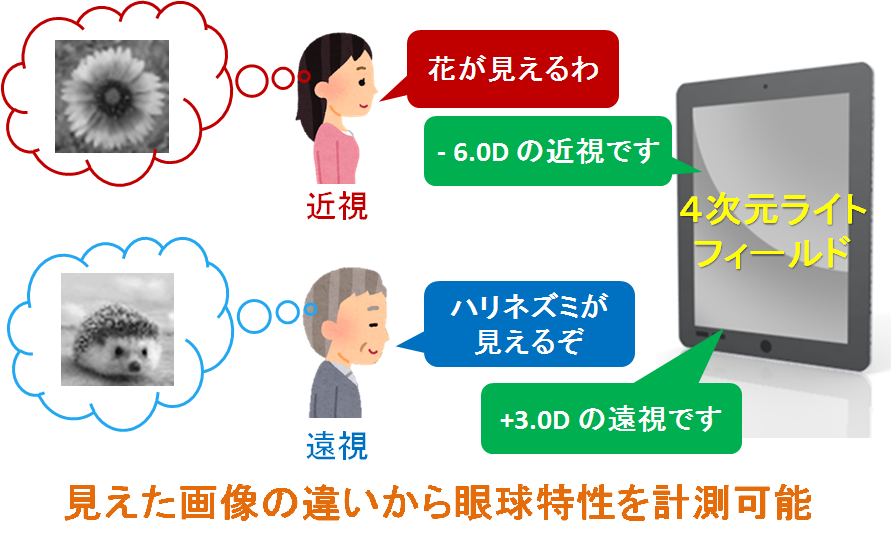
In this study, we are examining a new vision measurement method that can accurately measure the user's visual acuity characteristics simply by observing on a light field display.
Although conventional visual acuity measurement using Landolt's ring (circle partially missing) can measure rough visual acuity of the user, it has not been possible to measure fine characteristics such as myopia and hyperopia. However, in this research, this is realized by using a special display called light field display. A light field display is a display that can output different light from each pixel in each direction, and is used for stereoscopic vision and so on. In stereovision application, the user perceives three-dimensional information by presenting different images to the right and left eyes respectively, but in this study, this is further extended to present different images for each user's eyesight I have proposed a method. As a result, accurate vision characteristics can be measured simply by declaring the image observed by the user.
<< MIRU Interactive Presentation Prize >>
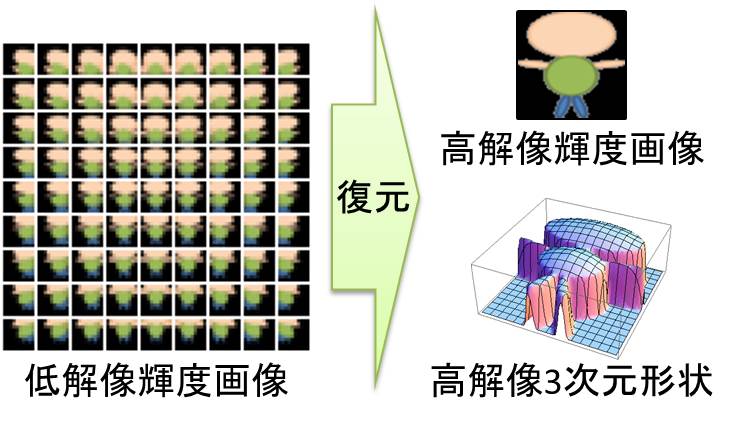
Super-resolution 3D reconstruction based on time series images
In this research, we are examining the method to estimate 3D shape more precisely than before.
When 3D reconstruction is performed using the stereo method, a sparse 3D shape can be reconstructed by finding a set of corresponding points from multiple images. However, when the resolution of the image to be used is low, the features of the image deteriorate, and as a result, it becomes impossible to find corresponding points between the images. This makes it difficult to estimate 3D shapes from images.
In this research, we extend the technique of generating high resolution images from multiple low resolution images called image super resolution to three-dimensional reconstruction, and estimate high resolution three-dimensional shapes from multiple low resolution images I'm considering how to do it. This makes it possible to estimate a precise 3D shape even if the resolution of the image used is low.
Reconstruction of 3D shape and motion from inconsistent images
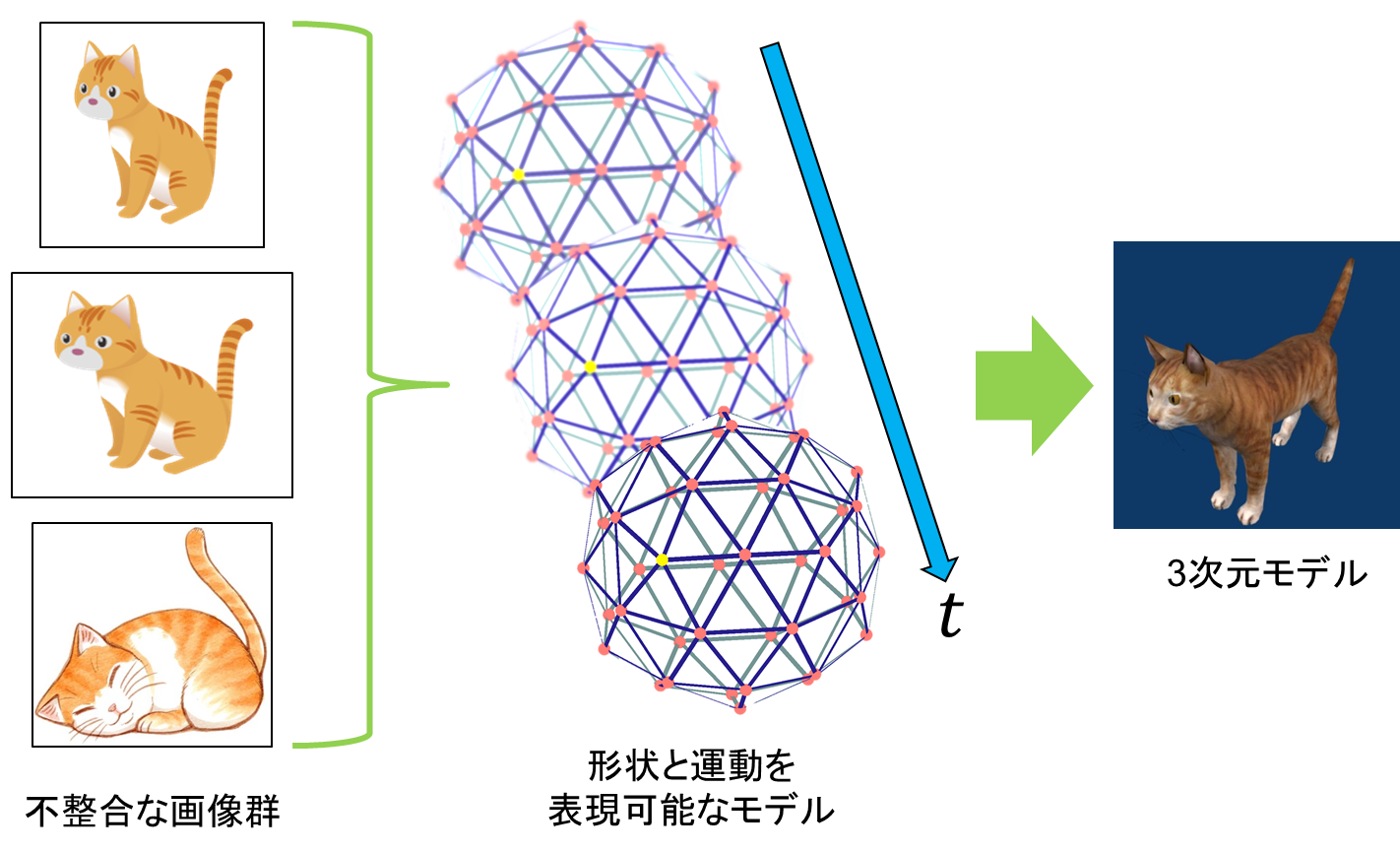
In this research, we are researching a method to simultaneously restore the three-dimensional shape and the motion of an object from mutually inconsistent image groups.
Recently, 3D models that represent 3D objects in detail have been used in various fields. The creation of such 3D models has required special techniques and a great deal of cost. Therefore, in this research, as a method of creating a 3D model more easily, we are examining a method of constructing a 3D model from hand-drawn images such as illustrations.
When restoring 3D shapes based on hand-drawn images, it is not possible to apply the stereo method (method to perform 3D restoration from images taken from different viewpoints) used for general 3D restoration. This is because hand-drawn images are not created based on complete three-dimensional information, so even if you draw images of different viewpoints, there will be a three-dimensional inconsistency between the images. Therefore, in this research, we consider that such an inconsistency is the motion of an object, and propose a model that can simultaneously express shape and motion.
Furthermore, we are researching estimation methods based on energy minimization using this model. This technique makes it possible to estimate the 3-D shape and motion occurring between images even from inconsistent hand-drawn images.
Realization of image super resolution using variable exposure camera
In this research, we are working on the development of a new camera system for acquiring a very high resolution HDR (High Dynamic Range) image.
In recent years, a technique called Computational Photography has been widely researched to acquire images more efficiently than conventional camera systems by integrating and reconstructing an imaging system and an image processing system. In our laboratory, we are developing a new variable exposure camera to acquire HDR images efficiently. This variable exposure camera realizes exposure control in pixel units that can not be realized with conventional cameras, and this enables effective capture of images with extremely high contrast.
In this research, we are researching on image super resolution to obtain higher resolution images using this variable exposure camera. This will enable the variable exposure camera to capture high contrast and high resolution images.
Estimation of wavefront aberration from incomplete Hartmann image
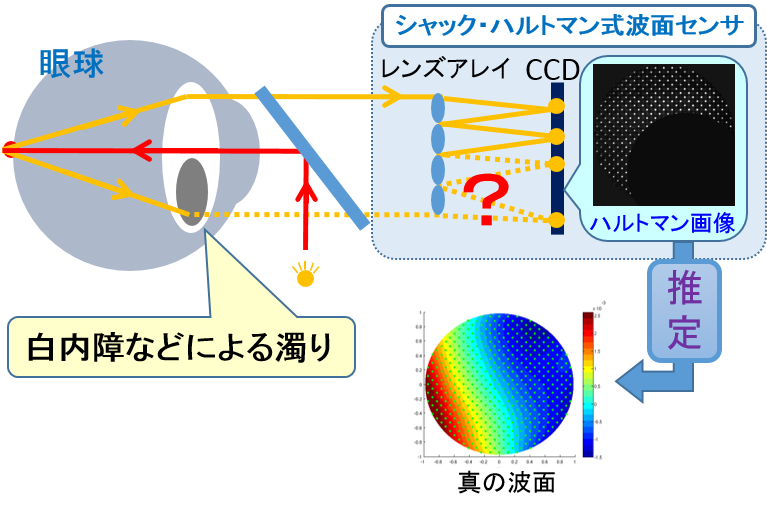
We are researching technology to properly measure the characteristics of a lens, even if there are dirt or defects on a part of the lens. This technology can be used to measure the eye characteristics of cataract sufferers.
In recent years, a new characteristic measurement method using a measuring instrument called a wavefront sensor has been studied in order to measure the refraction characteristic of the light of the eye in more detail. With this wavefront sensor, it is possible to measure the lens characteristics in detail by using the wave dynamic properties of light. However, with this wavefront sensor, if turbidity occurs in the lens (quartz) due to a cataract or the like, that portion can not be measured properly, and as a result there is a problem that accurate measurement of the entire lens can not be performed.
In this research, we propose a method to estimate the wavefront of lossless light from wavefront information including defects by introducing an approximate expression by parametric function and regularization at estimation. This technology makes it possible to measure the lens's inherent refractive properties even in cataract conditions.
Luminance difference stereo method using luminance derivative
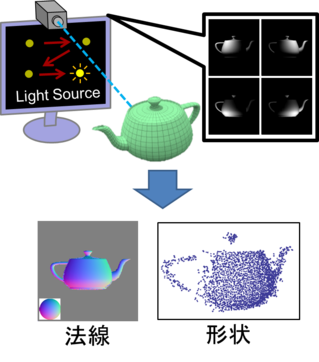
One of the methods to restore 3D shape is photometric stereo method which restores the shape from multiple images taken in different light source environment. In the normal photometric stereo method, the light source needs to be placed far enough (infinity light source), so a large space is required for shape measurement. On the other hand, although the illuminance difference stereo method corresponding to the case where the light source is placed close (proximity light source) has also been proposed, there is a problem that the calculation time increases because the nonlinear calculation is required for shape estimation.
In this research, by focusing on the change in luminance (luminance differentiation) when the light source is slightly shifted, we proposed a method to perform the photometric stereo by linear calculation in the proximity light source. In addition, we proposed a method for acquiring images with high accuracy by using a display as a light source. By using these technologies, it is possible to restore the shape of the object easily and quickly using only one display and one camera as shown in the figure.
HDR image generation using variable exposure camera
We are researching technology to acquire HDR images without whiteout and black crushing from a single image.
In the conventional method, HDR images were generated by combining multiple images, so there was a problem that combining in a scene with motion could not be performed properly. In this study, we constructed a variable exposure camera using LCoS, and proposed a new exposure method that controls the exposure in pixel units. A variable exposure camera is a new camera that assumes a control in which the exposure time of each pixel changes according to the input energy by fixing the brightness value. This allows you to measure input energy from the exposure time.
This technology makes it possible to obtain an image that allows you to see where overexposure or overexposure occurs during normal shooting.
<< MIRU Frontier Prize >>
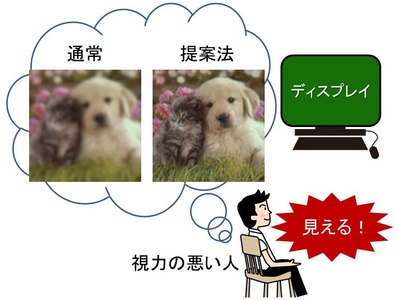
Virtual vision correction display based on pre-blurring restoration
We are researching image processing technology for displays that allow people with poor vision to observe an image without blurring with their naked eye.
Bokeh occurs in the eyes of people with poor vision because light refracted by the lens does not form an image on the retina. In general, this blurring can be expressed by the convolution of the blurring function with the input image. So, in this research, we deconvolve this blur function in advance to generate an image that cancels out blur during observation. By presenting this image, the image that was blurred with the naked eye can be seen clearly without using glasses or contact lenses.
This technology can be applied to screens of PCs and smartphones.
3D shape reconstruction of animal

In recent years, methods for restoring the shape of objects in real space from images have been widely studied. However, for objects whose shape and orientation change dynamically, it has been difficult to recover three-dimensional shapes due to factors such as calculation processing time. In this study, we used the photometric stereo method to estimate three-dimensional shape using images taken under different light source environments, and used to restore the shape of the object from the one-shot image.
Since the photometric stereo method requires three or more input images with different light source directions, it is not usually possible to obtain sufficient input in one shot. Therefore, we used images taken by simultaneously projecting multiple color light sources of different wavelengths such as red, green and blue. By separating this image for each wavelength component, the photometric stereo method was applied to the image shot in one shot. At this time, the reflectance of the target object can be estimated in advance, and the normal of the dynamically changing object can be estimated using it.
Vehicle approach detection using collision time calculation based on luminance information
We are researching to capture the road surface illuminated by the headlights of a vehicle with an onboard camera and calculate the arrival time of other vehicles to the intersection from the luminance information.
By applying a proximity light source model as an approximate model of the headlights of a vehicle, it is not necessary to obtain distance information directly. Also, by combining it with the Time to Contact method that estimates arrival time from image information, it is possible to obtain arrival time only from the luminance information in the image.
This technology makes it possible to control traffic accidents at poor intersections.
Multiple image projection using multiband projector
Since human vision usually responds strongly to the three colors of RGB, these three bands have often been used in display systems such as conventional displays and projectors. However, in the natural world, there are innumerable colors that can not be expressed by these three bands, and the amount of information that can be expressed by conventional display systems is limited.
Therefore, in this research, we constructed a multi-band projector that can emit light with four or more bands, and proposed a method to embed more information into the projection light. In particular, by utilizing the differences in spectral sensitivity characteristics that exist between humans and cameras, we can realize a new information presentation method that presents different images to different observation systems, as shown in the figure.
Raindrop removal based on camera array video
In this study, raindrops adhering to the windshield of a car are virtually removed from the image obtained from the onboard camera and presented to the driver.
Raindrops are located closer to the camera than the background, so even a slight change in the position of the viewpoint changes the position in the image significantly. Therefore, in this research, we construct a camera array by arranging a large number of cameras regularly, and use the images of various viewpoints obtained by it to perform raindrop removal by replacing the raindrop portion with a non-raindrop portion.
By applying this technology to in-vehicle cameras, it will be possible to secure the driver's visibility even on rainy days.
Three-dimensional reconstruction in scattering space
We are researching to generate an image with a clear view, using an image taken in an environment where there are obstacles such as fog and smoke.
We have proposed a scattering medium model so that the light as it passes through the scattering medium, such as fog or smoke, represents the change. In the proposed model, it is assumed that the particles emit light that is reflected by the particles present in the medium. The assumption is that the scattering medium can be expressed by a simple equation.
Using this model, it is also possible to restore the scattering space and its object by decomposing the scattering space into voxels and calculating the luminous intensity of each voxel.
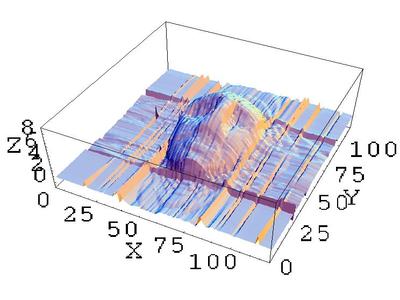
Super-resolution 3D shape enhancement using multi-projector

At present, a method has been proposed in which multiple projector lights are superimposed and projected onto a target object to highlight abnormal shapes with high accuracy, but the accuracy of this method depends on the projector resolution. Therefore, in this research, we propose a method to enhance the projector resolution by super-resolution projection and to perform shape enhancement with higher accuracy.
Two important technologies are used in this research. One is a technology called coded projection, and while conventional image processing requires measurement with a camera or a computer, three-dimensional information can be presented at the speed of light only by projecting images from a plurality of projectors. I will. The other is super-resolution technology, which can improve the resolution of superimposed images in a simulated manner by using a shift of less than one pixel that occurs when projecting from multiple projectors toward the same area .
This research is very useful in the detection of small industrial product anomalies and the detection of road surface irregularities.
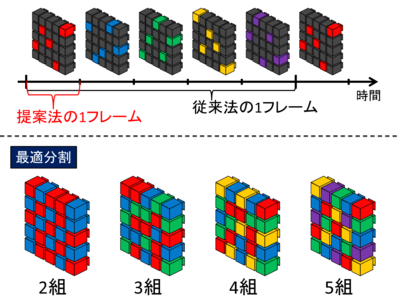
High frame rate 3D reconstruction using split imaging with camera array
We are conducting research on 3D reconstruction at high frame rates based on images obtained from a camera array in which a large number of cameras are arranged in a grid.
A camera in a camera array is divided into a plurality of camera groups, and imaging is performed while shifting the imaging timing for each camera group, thereby performing three-dimensional reconstruction at a high frame rate without shortening the exposure time. At this time, by optimizing the camera grouping, it is possible to suppress the decrease in 3D restoration accuracy due to the reduction in the number of cameras used for restoration.
This research can be applied to high-speed 3D analysis of motion.
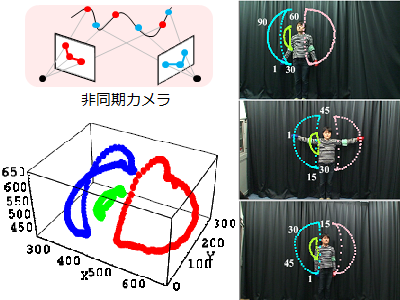
High density 3D reconstruction using asynchronous multi-camera
This is an improvement in the accuracy of 3D reconstruction aimed at measuring the movement of balls and cars.
In the conventional method, multiple cameras had to be synchronized, and high-speed motion could not be restored correctly. In this research, it is noted that it is possible to obtain independent information from each camera by using an asynchronous multi-camera, and that the movement of the object and the shift of the photographing time can be separated in the frequency space We propose a new projection model to project.
This makes it possible to restore high-frequency motion that exceeds the camera frame rate, resulting in more accurate 3D reconstruction.
<< MIRU Frontier Prize >>
3D shape enhancement by multi projector
This research is a research that uses projectors to detect anomalies in target objects.
By calculating the overlap of multiple projector lights, it is possible to generate a projector image in which the surface of the reference object is colored white, and in other parts colored in highly saturated colorful colors.
This makes it possible to visually detect abnormalities such as irregularities on the surface of the target object, and in theory, it is possible to detect abnormalities in millimeter units. Moreover, since this detection method is performed at the speed of light, it is considered to be applied to product inspection at a factory.
Imaging of 4D ray space by coded aperture and ray split imaging
In recent years, research has been actively conducted on "light field cameras" that can freely refocus images after shooting. In this camera, by devising the camera and the shooting method, it is possible to obtain information called light field (4D ray space) rather than a simple photo, and to present various images after shooting.
However, there are remaining problems such as difficulty in achieving high resolution by the conventional method and an increase in imaging time due to high resolution.
In this research, the time taken to acquire the light field is shortened while the resolution of the light field that can be acquired is enhanced.
Computational photography
In recent years, research is underway to restore depth blur and motion blur by deconvolution using camera blur function (PSF). In particular, advances in computational photography research have made it possible to generate an omnifocal image and control the depth of field even in 3D scenes where the depth of the subject is not constant.
This study shows that moving the camera during exposure makes the PSF invariant regardless of the direction and size of the object movement in the image, and by using this property, the direction of the object movement and It indicates that motion blur can be restored regardless of the size.
It is already known that this method of imaging can restore the depth blur of an object with any depth. Therefore, with the proposed method it is possible to simultaneously restore the depth blur and motion blur of an object with any motion present at any depth.
Reconstructing sequential patterns without knowing image correspondences
In this research, we propose a method to simultaneously perform camera calibration and 3D reconstruction from multiple uncorrelated images with time series patterns and repetitive patterns.
To do this, we use an affine camera to consider the pattern shift and the Fourier transform of the target object. In normal space, the correct correspondence can not be obtained between the two images, but the shift amount can be calculated by deriving high dimensional multi-view geometric constraints that hold in the frequency domain.
Using the proposed method, it is possible to generate time-series patterns and texture patterns of arbitrary viewpoint images, which can be applied to mixed reality and so on.
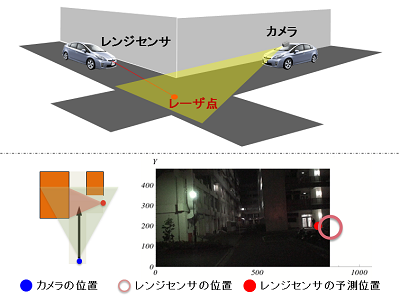
Position presentation of blind spot vehicles using multi-dimensional multi-view geometry
In this research, we propose a method to measure the position of the other vehicle with a range sensor and a camera at an intersection where blind spots such as alleys occur.
This is a relative position measurement technology that measures the relative position between vehicles by performing sensor coordination between different types of sensors: range sensors and cameras. Range sensors make it possible to conduct stable observation at night and even on uniform road surfaces.
This method can be expected to greatly contribute to the realization of safe driving, such as the reduction of collision collisions that are likely to occur in blind spots.
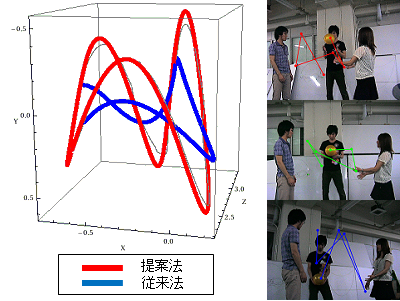
Abnormal driving detection using spatiotemporal multi-view geometry
In this research, in order to reduce driver's visual burden and prevent traffic accidents, we propose a method of detecting abnormal driving using multiple cameras with spatiotemporal geometry.
Spatio-temporal multi-view geometry takes relationships between time-series images taken from multiple cameras. Therefore, we designed a camera to be installed on all running vehicles to acquire the correspondence between them and detect abnormal driving. In the experiment, we could recognize abnormal driving such as lane change and fluttering.
In the future, it is expected to be used as a method to prevent traffic accidents in the field of ITS (highway traffic system).
Optically matched object composition
In recent years, mixed reality technology that integrates the real world and the virtual world has been active. In mixed reality, when combining an object to a real scene, we apply shadows and shadows to the combined object and perform a method that combines without discomfort.
What is needed are mainly the unevenness information of the object to be synthesized and the light source information of the scene to be synthesized. Using a method called photometric stereo method (PhotoMetricStereo), information on unevenness of the object to be synthesized is estimated, and light source information of the scene to be synthesized is estimated using the shadow of a sphere or the like placed in the scene in advance, I will.
This technology can be applied to movie production and simulation of surgery.
3D object recognition based on coded projection
Although recognition of 3D objects requires searching for corresponding points between multiple images, it has the disadvantage that false responses occur. Therefore, in this research, we propose a method to recognize 3D objects without causing positional deviation by projecting light from multiple projectors.
In this research, we use a technique called coded projection, which projects special patterns from multiple projectors. The projector light can be presented without causing a position shift on the object, so there is no need to search for corresponding points.
This technology makes it possible to recognize 3D objects without causing false response problems.
Simultaneous restoration of depth blur and motion blur by space-time coding
In recent years, research has been actively conducted to remove blur in images. In general, blurring in an image can be divided into depth blurring that occurs when the subject is not in focus and motion blurring that occurs when the subject moves.
In this research, we apply coded aperture to the camera aperture and change the pattern during exposure to eliminate both blurs simultaneously.
This research makes it possible to clearly capture each moving object at different distances from the camera.
Object enhancement using multi-projector
In this research, we aim at emphasizing and presenting a specific three-dimensional space using projection light from multiple projectors, and propose a method for deriving projection patterns for that purpose.
In this method, by projecting a specific pattern from the projector, it is possible to realize 3D space highlighting without any image acquisition with a camera or 3D restoration processing with a computer. This enables spatial highlighting at the speed of light.
By using this method, it is possible to mount it on a car and highlight the uneven surface of the road, or use it in a factory production line to detect defective products.
Thickness estimation of translucent objects based on subsurface scattering
Computer vision often uses a model that assumes that the object is opaque.
However, there are many semi-transparent objects in reality, and when a semi-transparent object is illuminated by light, a phenomenon occurs in which light enters inside and is emitted again from a certain surface. This phenomenon is called subsurface scattering, and in this study we propose a method to estimate the internal structure of a semitransparent object by using the subsurface scattering.
The distribution of light emitted by subsurface scattering when light is applied to a translucent object depends on the material inside the object. By using the difference, you can get the internal characteristics and structure of the object.
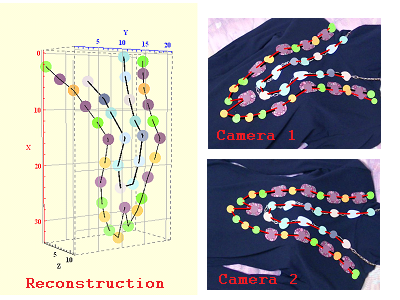
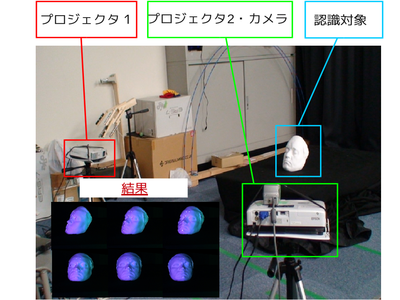
Camera calibration from multi-view geometry and asynchronous camera images in frequency domain
This is a research that performs camera calibration and three-dimensional restoration of object trajectories from images taken with asynchronous cameras.
Generally, in order to perform 3D reconstruction using the stereo method, it is necessary to capture the same 3D point with multiple cameras. Therefore, 3D reconstruction can not be performed by the conventional method when a shift occurs in the shutter timing.
In this research, by considering multi-view geometry in frequency space, it becomes possible to calibrate the camera and restore the object from the image including the shift in the shooting timing.
It is thought that this will realize the advancement of image processing technology such as advanced gesture recognition.
Epipolar geometry virtual raindrop removal on vehicle side mirror
In the past, the removal of raindrops in car glass has been done using physical methods such as water repellents. However, there is a problem with water repellents that raindrops do not scatter when the vehicle speed is slow or light rain.
Therefore, in this research, instead of physically removing the raindrops, a method of photographing the side mirror using a car-mounted camera and virtually removing the raindrops using the obtained time-series image data is proposed. I will propose.
By presenting the image created in this way to the driver, it is possible to remove raindrops without being affected by conditions such as the vehicle speed, and the driver's visibility can be maintained stably.
3D shape reconstruction based on shadows and shadows projected on arbitrary surface
The 3D shape is restored using light and shadow information.
You can get information about the unevenness of the object from the shadows that occur when shooting the object at various light source positions. A method to obtain shadow information from multiple images with different light source positions and restore the object shape based on it is called Shape-from-Shadows.
In this research, we apply the existing method to restore three-dimensional shape with unknown light source environment, and both object shape and light source position simultaneously at high speed and high accuracy under the condition that both shape of imaging target and light source position are unknown We propose a method to estimate to.
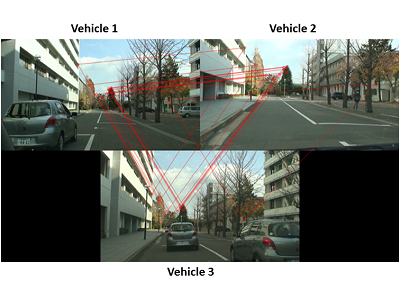
Generation of virtual image of blind spot using inter-vehicle image communication
This research is a research that presents the driver in an easy-to-understand manner by coordinating the cameras mounted on multiple vehicles with the situation of the blind spot that was obscured by other vehicles when waiting for a right turn at an intersection.
In this research, using the vanishing point of the oncoming vehicle reflected in the image of the own vehicle camera, the information of the gaze direction relative to the oncoming vehicle camera is calculated. Then, based on the information, the image of the oncoming car camera is virtually rotated and combined with the image of the own car camera to generate a consistent image.
By using this technology to assist the driver's vision when turning right, it is possible to prevent an accident in advance.
Projective reconstruction and virtual keyboard with uncalibrated camera and uncalibrated projector (Virtual piano)
A virtual piano is a system that can virtually display the keyboard of an instrument on a desk using a projector and play as if it were a real piano.
In this system, the projector is used to project the keyboard of the instrument onto the screen placed on the desk. Then, by using the camera to recognize the situation of the user's performance, the sound corresponding to the pressed keyboard is produced. In addition, the position of the hand can be determined in three dimensions by using a camera and a projector, so the speed of moving the finger can be calculated. In addition, you can recognize the strength to press the keyboard from the speed of the finger, you can also reproduce the strength of the sound playing the keyboard.
Stereo restoration and virtual modeling in rotational symmetric space (Virtual rokuro)
Virtual Rokuro is a system that can make a virtual creation of Rokuro look like a real thing.
In this system, a marker is placed at the position where you want to display the wheel in real space, and two or more cameras are placed toward the marker, virtually through the head mounted display worn by the user, at the marker position. You will see the wheel you made. By putting your hand towards the wheel, you can make it a real wheel.
Furthermore, it is possible to realize things that can not be realized in real world, such as sparks and music being emitted from the position where they are scratching, by using mixed reality technology.
Lane departure warning by camera image
In this research, we propose a method of estimating the vehicle position in the driving lane with uncalibrated camera images that do not require camera calibration.
In this research, we focused on the fact that there are various sets of parallel lines including lanes in the environment where a car travels on a road. By using these parallel lines to virtually project the camera viewpoint onto the traveling lane, the relative position information of the camera in the traveling lane is calculated.
Although this method does not know the absolute position, it is considered that only relative position information is sufficient when considering applications to lane departure warning and departure prevention control.
3D reconstruction and sharing of mixed reality space using mutual projection of multiple user cameras (Virtual battle system)
A virtual battle system is a system that allows multiple users to play in virtual space.
In the system of this research, each user wears a head mount display and has a light saver pattern that appears in the movie "STAR WARS". Then a virtual light saver appears on the head mounted display. In addition, you can hear the sound effects by swinging the light saver.
This system can be constructed by calculating the 3D position of the light saver from the camera information.